Теория экономических информационных систем
ВВЕДЕНИЕ
Современные экономические системы для успешной конкуренции в рыночных условиях требуют применения последних достижений науки и техники в области управления. Внедрение вычислительной техники, создание информационных систем различного назначения – это путь эффективного развития предприятия любого профиля.
В учебном пособии рассматривается понятия, описывающие экономическую информационную систему и ее компоненты, а также модели и методы создания и сопровождения ЭИС.
В первой главе определены основные понятия экономических информационных систем, классификация ЭИС, единицы информации, такие как атрибут, СЕИ, экономический показатель.
Вторая глава рассматривает синтаксические модели данных: реляционную, сетевую, иерархическую, модель инвертированных файлов. Дается сравнительный анализ моделей. Каждая модель анализируется с учетом применяемых информационных конструкций, допустимых операций и ограничений. Рассматривается реляционная алгебра и нормализация отношений. Представлены сетевые модели данных и алгоритм приведения к двухуровневой структуре сети, модель инвертированных файлов, как частный случай двухуровневой сетевой модели данных, а также основы организации иерархической модели данных.
В третьей главе рассматриваются методы организации данных: линейные и нелинейные. К линейным методам относятся последовательная организация данных и списковая. К нелинейным – древовидная и, как частный случай, бинарное дерево. Также представлен анализ методов по четырем критериям: времени формирования массива, времени поиска, времени корректировки и объему дополнительной памяти.
В четвертой главе рассматриваются семантические модели данных как средство моделирования предметных областей в экономике. К этому виду моделей относятся модель сущностей и связей и модель семантических сетей. Дается понятие тезауруса и показана его роль в формировании массивов экономической информации.
Предлагаемое учебное пособие построено в соответствии с требованиями государственного образовательного стандарт высшего профессионального образования для специальности «Прикладная информатика (в экономике)».
УЧЕБНАЯ ПРОГРАММА ДИСЦИПЛИНЫ
Программа дисциплины отражает требования Государственного стандарта по специальности 351400 «Прикладная информатика (по областям).
Содержание программы дисциплины «Теория экономических информационных систем» определяется следующими темами и дидактическими единицами.
Основные понятия экономических информационных систем
Информационная система в общем виде: понятие информации; понятие системы; понятие экономической информационной системы; классификация ЭИС. Компоненты экономических информационных систем. Операции над единицами информации: экономические показатели.
Модели данных
Реляционная модель данных: основные понятия реляционной модели данных; реляционная алгебра; операции над отношениями с применением конструкций языка SQL; функциональные зависимости и ключи; нормализация отношений; вторая и третья нормальные формы.
Ациклические базы данных.
Сетевая и иерархическая модели данных: основные понятия сетевой модели данных; организация веерного отношения в памяти ЭВМ; алгоритм получения двухуровневой структуры сети; иерархическая модель данных.
Сравнение моделей данных.
Модель инвертированных данных и информационно-поисковые системы.
Методы организации данных
Анализ алгоритмов и структур данных; сравнение методов организации данных; поиск в последовательном массиве; корректировка последовательного массива; цепная (списковая) организация данных; цепной каталог; древовидная организация данных.
Моделирование предметных областей в экономике
Семантические модели данных; тезаурусы экономической информации.
ГЛАВА 1. ОСНОВНЫЕ ПОНЯТИЯ ЭКОНОМИЧЕСКИХ ИНФОРМАЦИОННЫХ СИСТЕМ
§ 1.1. Информационная система в общем виде.
Понятие информации
Степень значимости информации для общества в целом и для экономики предприятия в частности трудно переоценить. По данным ЮНЕСКО более половины занятого населения наиболее развитых стран принимает непосредственное участие в процессах производства и распределения информации, а в ряде стран до половины национального продукта связано с информационной деятельности общества.
Существующие понятия определения информации чаще всего рассматривают это понятие в более узком смысле. Поэтому вряд ли возможно сформулировать одно точное определение этого понятия.
Норберту Винеру принадлежит определение информации как нарушенного однообразия. На рубеже 80-х годов ХХ века впервые в истории цивилизации усилия, затраченные на получение и переработку знаний, превысили расходы на получение энергии, сырья, материалов, технологического оборудования и предметов потребления. При этом за информацией закрепляется статус одного из главных ресурсов научно-технического и социально-экономического развития морового сообщества. Поэтому сегодня информационный ресурс оценивается как производственный, национальный.
Взгляд на информацию как на ресурс, аналогичный материальным, трудовым и денежным ресурсам, отражается в следующем определении:
Информация - новые сведения, позволяющие улучшить процессы, связанные с преобразованием вещества, энергии и самой информации.
Информация не отделима от процесса информирования, поэтому необходимо рассматривать источник информации и потребителей информации. Роль потребителей информации очерчивается в таком определении.
Информация - новые сведения, принятые, понятые и оцененные конечным потребителем как полезные.
Информацией являются сведения, расширяющие запас знаний конечного потребителя.
Предмет компьютерной информации – это информационные ресурсы, которые в ст. 2 Федерального закона от 20 февраля 1995 года «Об информации, информатизации и защите информации» рассматриваются как отдельные документы и массивы документов в информационных системах. Эти ресурсы, согласно ст.2 Закона содержат сведения о лицах, предметах, событиях, процессах, населении, независимо от формы их представления.
При исследовании природы информации обычно приняты два основных подхода.
1. Атрибутивный трактует информацию как свойство движущейся материи, состоящее из структурности, упорядоченности и разнообразии ее состояний.
Признание всеобщности той стороны реальных объектов и процессов, которая отражается в понятии информация, как проявление атрибутивных свойств объектной реальности – суть этой концепции, ее отличительная черта.
2. Функционально-кибернетический рассматривает информацию как свойство определенного класса информационных систем, которое возникает и обогащается в процессе становления, развития этих систем, их функционального взаимодействия между собой и внешним миром. Такими системами являются, во-первых, живые организмы их сообщества, во-вторых, человек и человеческое сообщество и, в-третьих, интеллектуальные системы.
Выделяются три фазы существования информации.
1. Ассимилированная информация - представление сообщений в сознании человека, наложенное на систему его понятий и оценок.
2. Документированная информация - сведения, зафиксированные в знаковой форме на каком-то физическом носителе.
3. Передаваемая информация - сведения, рассматриваемые в момент передачи информации от источника к приемнику.
В дальнейшем будем рассматривать только документированную или передаваемую информацию. Подавляющая масса информации собирается, передается и обрабатывается с помощью знаков. Знаки - это сигналы, которые могут передавать информацию при наличии соглашения об их смысловом содержании между источниками и приемниками информации. Набор знаков, для которых существует указанное соглашение, называется знаковой системой. Многие знаковые системы, естественно, нельзя четко ограничить, однако при обработке информации на электронных вычислительных машинах (ЭВМ) наличие точного перечня знаков обязательно.
Правильное восприятие информации конечным потребителем может быть затруднено из-за наличия различных помех, называемых информационным шумом.
Различаются три разновидности шума и соответственно три информационных фильтра, блокирующих этот шум.
1. Синтаксический фильтр. В последовательности знаков, хранимых на носителе или передаваемых, могут быть обнаружены участки, относительно которых отсутствует соглашение о придании им смысла.
Эти участки составляют синтаксический шум, и они распознаются синтаксическим фильтром. Фильтр содержит набор решающих правил, позволяющих различать правильные (осмысленные) и неправильные (бессмысленные) последовательности знаков.
2. Семантический фильтр. Первый аспект семантического шума связан с отсутствием новизны в получаемом сообщении. Иначе говоря, сообщение не расширяет знаний потребителя. Второй аспект семантического шума связан с прохождением ложного сообщения через синтаксический фильтр. Допустим, что сообщение "Количество студентов, поступивших в 2001 году на факультет менеджмента и бизнеса в группу 1417 равно 3 человекам" дважды искажено так, что вместо цифры 5 воспринято 7 и вместо 25 воспринято 3. Первое искажение может быть зарегистрировано синтаксическим фильтром, только если группа с кодом 1417 вообще не существует на факультете, а второе искажение синтаксический фильтр не заметит. Такие искажения должен обнаруживать семантический фильтр. Он проверяет соответствие контролируемого сообщения с уже имеющейся информацией. Если в нашем примере установлено, что количество студентов в группе должно превышать 20 человек, а для группы 1415 она составляет 3 человека, то после исправления первой ошибки семантический фильтр обнаружит вторую ошибку. Существенные для семантического фильтра взаимосвязи устанавливаются также предметными науками, например бухгалтерским учетом, экономической статистикой и др.
3. Прагматический фильтр, говоря в общем, устанавливает степень ценности информации для потребителя. Элементы прагматической оценки обычно охватывают полноту информации (исчерпывающее отражение явления), ее своевременность, компактность (возможна меньшая длина сообщения), употребимость (число потенциальных потребителей) и доступность.
Информация на пути от источника к потребителю проходит через ряд преобразователей - кодирующих и декодирующих устройств, вычислительную машину, обрабатывающую информацию по определенному алгоритму, и т. д. На промежуточных стадиях преобразования семантические и прагматические свойства сообщений отступают на второй план ввиду отдаленности потребителя, поэтому понятие информации заменяется на менее ограничительное понятие "данные".
Данные представляют собой набор утверждений, фактов и/или цифр, лексически и синтаксически взаимосвязанных между собой.
Лексические отношения (часто называемые парадигматическими) отражают постоянные связи в структуре языка, например, род - вид, целое - часть. Связи между отдельными частями сообщения отражаются синтаксическими (синтагматическими) отношениями. Данные безразличны к семантическому и прагматическому фильтру. В тех случаях, когда различие между информацией и данными нет нужды подчеркивать, они употребляются как синонимы.
Чтобы определить понятие “экономическая информация”, надо очертить рамки экономических процессов. В наиболее общей форме экономическими процессами являются производство, распределение, обмен и потребление материальных благ. Информация об указанных процессах называется экономической информацией.
Для обработки экономической информации характерны сравнительно простые алгоритмы, преобладание логических операций (упорядочение, выборка, корректировка) над арифметическими, табличная форма представления исходных и результатных данных.
К важнейшим признакам, по которым обычно осуществляется классификация циркулирующей экономической информации, относятся:
1. Отношение к данной управляющей системе. Этот признак позволяет разделить сообщения на входные, внутренние и выходные.
2. Признак времени. Относительно времени сообщения делятся на перспективные (о будущих событиях) и ретроспективные. К первому классу относится плановая и прогнозная информация, ко второму - учетные данные. По времени поступления разделяются периодические и непериодические сообщения.
3. Функциональные признаки. Формируется классификация по функциональным подсистемам экономического объекта. Например, информация о трудовых ресурсах, производственных процессах, финансах и т.п., в другом разрезе - на данные планирования, нормирования, контроля, учета и отчетности.
Надо констатировать, что не существует меры информации, равно применимой на всех стадиях обработки информации.
Остается единственная возможность - учитывать количество обрабатываемых знаков, т. е. объем информации. Эта величина отражает, естественно, только внешнюю сторону информационных процессов.
Понятие системы
В условиях быстро меняющейся рыночной ситуации информационная поддержка любого предприятия должна соответствовать динамике изменений внешней и внутренней среды. Поэтому в настоящее время основой для решения задач обработки информации для принятия решений стал системный подход к анализу и построению информационной модели экономики. Как любая система, экономическая система охватывает комплекс взаимосвязанных элементов, действующих как единое целое.
Системой называется любой объект, который, с одной стороны, рассматривается как единое целое, а с другой — как множество связанных между собой или взаимодействующих составных частей.
Понятие системы охватывает комплекс взаимосвязанных элементов, действующих как единое целое. В систему входят следующие компоненты.
1. Структура
- множество элементов системы и взаимосвязей между ними. Математической моделью структуры является граф.
2. Входы и выходы - материальные потоки или потоки сообщений, поступающие в систему или выводимые ею. Каждый входной поток характеризуется набором параметров {x(i)}; значения этих параметров по всем входным потокам образуют вектор-функцию X. В простейшем случае Х зависит только от времени t, а в практически важных случаях значение Х в момент времени t+l зависит от X(t) и t. Функция выхода системы Y определяется аналогично.
3. Закон поведения системы - функция, связывающая изменения входа и выхода системы Y = F(X).
4. Цель и ограничения. Качество функционирования системы описывается рядом переменных u1, u2,..,uN. Часть этих переменных (обычно всего одна переменная) должна поддерживаться в экстремальном значении, например, mах u1. Функция ul = f(X,Y,t,... ) называется целевой функцией, или целью
В более расширенном толковании последнее определение системы формулируется как множество элементов, образующих структуру и обеспечивающих определенное поведение в условиях окружающей среды, что можно формулировать следующим образом:
S = ( Э1, Э2, Э3, Э4), где
Э1 – элементы, Э2 - структура, Э3 - поведение системы, Э4 – среда.
Вне зависимости от способов детерминирования системы, базисные принципы системного анализа предполагают вычленение элементарной основы, а так же выявление совокупности межэлементных взаимоотношений, которые и формируют, в свою очередь, новое интегративное качество, придают новому образованию целостность, позволяющую говорить о существовании системы.
 |
 |
Информационные потоки |
 |
Материальные потоки |
Системный подход позволяет представить процесс построения любой информационной системы в виде схемы, содержащей семь этапов (рис. 2) , которые определяют создание системы от постановки задачи до ее реализации.
Первый этап – формирование основных требований к системе на словесном (вербальном) уровне без должной формализации.
Второй этап – определение концепции решения проблем и задач или построения системы.
Третий этап – детализация общей задачи создания и применения системы описаний для перехода от словесных формулировок к схемному или логически взаимосвязанному описанию функций и задач системы, которое позволит разбить систему на основные составляющие ее части. В результате определится структурная схема системы.
 |
На первых трех этапах происходит формирование инфологической модели.
Четвертый этап – алгоритмизация методов и решений задач, стоящих перед системой, выбор моделей данных, математических и технологических решений.
Пятый этап – оптимизация решений, осуществляемая на основе дополнительного исследования предметной области и специфики решаемых задач. Этим заканчивается построение системы на логическом уровне проектирования.
Шестой этап – реализация системы. В терминах проектирования говорят о переходе к физическому (уровню) построения системы.
Седьмой этап – модернизация создания информационной системы, предусматривающая учет возможных ситуаций функционирования, а также тенденций развития программно-технологических средств.
Системы вообще и экономические системы в частности характеризуются следующими свойствами:
ü Целостность, т.е. согласованность цели функционирования всей системы с целями функционирования ее подсистем и элементов;
ü

ü Относительность, т.е. зависимость элементов, взаимосвязей, входов, выходов, целей и ограничений от целей исследования
ü Разнообразие (множественность)
ü Эмерджентность – возникновение у системы новых интегративных качеств, не свойственных элементам (подсистемам, частям).
Надо также иметь в виду, что система, как правило, имеет больше свойств, чем составляющие ее элементы. Так, предприятие обладает юридической самостоятельностью, а его подразделения - нет.
Понятие экономической информационной системы
Экономическая информационная система (ЭИС) представляет собой систему, функционирование которой во времени заключается в сборе, хранении, обработке и распространении информации о деятельности какого-то экономического объекта реального мира.
Информационная система создается для конкретного экономического объекта и должна в определенной мере копировать взаимосвязи элементов объекта.
Экономические информационные системы предназначены для решения задач обработки данных, автоматизации конторских работ, выполнения поиска информации и отдельных задач, основанных на методах искусственного интеллекта.
. Задачи обработки данных обеспечивают обычно рутинную обработку и хранение экономической информации с целью выдачи (регулярной или по запросам) сводной информации, которая может потребоваться для управления экономическим объектом.
Автоматизация конторских работ предполагает наличие в ЭИС системы ведения картотек, системы обработки текстовой информации, системы машинной графики, системы электронной почты и связи.
Поисковые задачи имеют свою специфику, и информационный поиск представляет собой интегральную задачу, которая рассматривается независимо от экономики или иных сфер использования найденной информации.
Алгоритмы искусственного интеллекта необходимы для задач принятия управленческих решений, основанных на моделировании действий специалистов предприятия при принятии решений.
Классификация ЭИС
Экономические информационные системы можно разделить на два больших класса: управляющие информационные системы (для управления технологическими процессами на предприятии) и системы организационно-административного типа (например, управление кадрами, технической подготовкой производства, автоматизация задач бухгалтерского учета и т.д.).
С функциональной точки зрения ЭИС делятся на информационно-поисковые системы – ИПС, системы обработки данных – СОД, автоматизированные системы управления – АСУ.
Назначением информационно-поисковых систем (ИПС) является поиск информации по заданному критерию, например, автоматизация кадровых служб, учет на складах, информационная система ГИБДД. При вводе в ИПС каждый документ подвергается индексированию. Под индексирование понимается процесс, состоящий из двух этапов:
- определение тем, отражаемых в документе;
- выражение этих тем на языке, принятом в ИПС.
Индексированы должны быть не только документы, но и запросы, поступаемые в ИПС.
Система обработки данных преобразует поток входной информации в поток выходной информации, предоставляемый органу управления объектом, который и принимает управленческое решение. Например, расчет заработной платы, расчет концентрации вредных веществ, выбрасываемых в атмосферу каким-либо предприятием.
Если СОД способна выполнять выбор управленческих решений, то она становится автоматизированной системой управления – АСУ.
В АСУ используются экономико- математические методы, методы экспертных оценок, на основе которых осуществляется моделирование действий специалистов. С помощью АСУ можно решать задачи оптимального управления запасами, планирования, учета и контроля.
Создание АСУ требует длительного времени и может проходить в несколько этапов. При искусственном разделении АСУ на функциональные составляющие руководствуются следующей классификацией в процессе принятия управленческих решений.
Первый уровень – выполнение учетно-информационных функций: сбор, регистрация, хранение, обработка, выдача информации о завершении производственных операций. Например, информационное сопровождение движения строительных материалов, машин и автотранспорта, выполнения объемов работ, поступления средств и т.д. На первом уровне автоматизированная система используется как информационная поддержка процесса принятия решения руководством организации.
Второй уровень – оперативно-управленческие функции: на основе данных первого уровня и анализа поступающей от подразделений информации решаются задачи оперативного управления предприятием, например, корректировка снабжения, переброса рабочей силы, механизмов и т.д.
Третий уровень – функции стратегического планирования: на основе данных первого и второго уровней и информации о региональной и глобальной экономической, социальной и политической конъюнктуры решаются задачи, связанные с деятельностью предприятия в ближайшем будущем: прогноз доходов предприятия на относительно длительный период времени, выбор заказчиков, корректировка профиля предприятия.
Деление ЭИС на практике оказывается весьма условным и чаще всего может сочетать в себе признаки и ИПС, и СОД и АСУ.
В ЭИС могут применяться два режима решения задач – пакетный и диалоговый.
Пакетный режим
обработки данных характеризуется рядом недостатков. Так, потребитель информации обособлен от процесса ее обработки, что в некоторых ситуациях вызывает у него сомнения в правильности исходных данных и результатов в применяемых алгоритмах.
Пакетная система снижает также оперативность принятия решений на управляемом объекте.
При диалоговом режиме работы происходит обмен сообщениями между пользователем и системой. Роль “активного” элемента пользователь и система выполняют попеременно. ЭИС активна от момента завершения ввода информации и команд пользователем до завершения обработки команды (запроса). Пользователь обдумывает результат обработки запроса и вводит данные для следующего запроса. Следует отметить, что последовательность команд, выдаваемых пользователем в диалоговом режиме работы, не является фиксированной заранее, а существенно зависит от результатов ранее выполненных команд.
Элементарным процессом при пакетной обработке является задание при диалоговой обработке - транзакция (взаимодействие). Задание содержит одну или несколько программ, выполняемых в определенной последовательности. Транзакция обычно представляет одну команду информационного процессора.
Необходимость диалога с системой возникает при решении экономических задач с многовариантной логикой, когда пользователь имеет возможность определять наиболее перспективные варианты решения задачи и постоянно следить за осмысленностью вычислений, производимых системой. Типичной диалоговой задачей можно считать расчеты по распределению ресурсов между несколькими потребителями.
|
Орган управления |
Орган управления |
|||
    |
||||
|
Система обработки данных |
|
Автоматизированная система управления |
||
   |
||||
|
Управляемый объект |
Управляемый объект |
|||

Рис. 3 б. Схема функционирования информационно-поисковой системы
По способу распределения вычислительных ресурсов
выделяются локальные и распределенные ЭИС. Локальная система использует одну электронно-вычислительную машину, а в распределенной системе организуется взаимодействие нескольких ЭВМ, соединенных между собой каналами связи.
Распределенная информационная система представляет собой объединение информационных систем, выполняющих собственные, не зависимые друг от друга функции, с целью коллективного использования информационных фондов и вычислительных ресурсов этих систем. Отдельные информационные системы, как правило, территориально удалены друг от друга.
Каждый из процессов в распределенной информационной системе может независимо обрабатывать локальные данные и принимать соответствующие решения. Отдельные процессы обмениваются информацией через сеть связи с целью обработки данных, расположенных в других узлах сети для собственных или коллективных нужд.
Наиболее распространенными схемами связи в распределенных ЭИС являются системы с центральной ЭВМ и системы с кольцевой структурой связей ЭВМ.
В заключение можно отметить, что вопросы использования экономической информации, методы управления экономическими объектами и методы принятия управленческих решений не рассматриваются в теории экономических информационных систем. Предполагается, что к моменту создания ЭИС указанные вопросы так или иначе решены. В теории ЭИС изучаются проблемы организации информации в системе и эффективной эксплуатации ЭИС.
§ 1.2. Компоненты экономических информационных систем
При решении любых задач с использованием ЭВМ требуется наличие ряда компонентов:
исходной и справочной информации для расчетов;
метода (алгоритма) решения задачи, записанного в виде программы, которая может быть выполнена на ЭВМ;
самой ЭВМ как исполнителя алгоритма;
пользователей, т.е. лиц, которые используют результаты решения задачи в своей профессиональной деятельности.
Компоненты информационной системы - это база данных, концептуальная схема и информационный процессор, образующие вместе систему хранения и манипулирования данными.
В окружающем нас мире выделяются материальные системы различного назначения. Все, что происходит в процессе функционирования материальных систем, может быть описано в форме сообщений.
Появление сообщений о событиях, происходящих в материальной системе, представляет собой информационное отображение материальных процессов.
Сообщение может быть выражено на естественном языке, однако часто применяют форматированные сообщения, когда выделяются опорные свойства (параметры) происходящего события и в сообщении приводятся названия свойств и их значения.
Пример сообщения.
10.12.01 в 8:00 состоялось занятие по ТЭИС в группе 1425.
Форматированный вариант этого сообщения
Название параметра................ Значение параметра
Дата.......................................... 10.12.01
Время....................................... 8:00
Группа...................................... 1425
Предмет.................................... ТЭИС
Подобных сообщений поступает много, они совпадают по названиям параметров и различаются по значениям параметров. В таком случае информацию удобно представлять в виде таблиц.
|
Дата |
Время |
Группа |
Предмет |
|
10.12.01 |
8:00 |
1425 |
ТЭИС |
|
10.12.01 |
9:30 |
1425 |
Эконометрика |
|
10.12.01 |
8:00 |
1435 |
Теория систем и системный анализ |
|
10.12.01 |
9:30 |
1445 |
Интеллектуальные информацион-ные системы |
База данных
(БД) - это набор форматированных сообщений, которые
являются истинными для соответствующей материальной системы;
непротиворечивы по отношению к друг другу и к концептуальной схеме.
Понятие базы данных можно применить к любой связанной между собой по определенному признаку информации, хранимой и организованной особым образом – как правило в виде таблиц. При этом возникает необходимость в выполнении рядя операций, в первую очередь это:
- добавление новой информации в существующие файлы;
- добавление новых пустых файлов;
- модификация информации;
- поиск информации;
- удаление информации;
- удаление файлов.
Сообщения в БД обычно являются форматированными и хранятся в виде единиц информации.
Единицей информации называется набор символов, которому придается определенный смысл. Это понятие относится в основном к базе данных, хранящей форматированные сообщения.
Минимально необходимо две единицы информации - атрибут и составная единица информации (СЕИ).
Атрибутом
называется информационное отображение отдельного свойства некоторого объекта, процесса или явления.
Любое сообщение записывается в форматированном виде как указание свойств (параметров) предметов, о которых мы говорим. Поэтому информационное отображение любого явления представляет собой набор соответствующим образом подобранных атрибутов.
Составная единица информации представляет собой набор из атрибутов и, возможно, других СЕИ.
Простейшими СЕИ являются таблицы, подобные приведенной выше. СЕИ позволяет создавать произвольные комбинации из атрибутов.
База данных ЭИС хранится в запоминающих устройствах вычислительной системы (ЭВМ). Хранимые представления данных очень часто не соответствуют первоначальному множеству форматированных сообщений. Однако сейчас при рассмотрении БД будем считать, что сообщения хранятся в виде таблиц.
Концептуальная схема (от слова concept - понятие) представляет собой описание структуры всех единиц информации, хранящихся в БД. Под структурой понимается вхождение одних единиц информации в состав других единиц информации.
В рамках нашего примера можно говорить о двух единицах информации - параметре (атрибуте) и таблице (СЕИ).
Предположим, что таблица Т соответствует всей базе данных. В концептуальной схеме должно быть указано, что БД состоит из Т, а Т содержит параметры Получатель, Отправитель, Изделие. Дата, Цена, Количество. Более содержательное представление о концептуальной схеме рассмотрим ниже.
Информационный процессор - это механизм, который в ответ на получение команды выполняет операции с БД и концептуальной схемой. Информационный процессор состоит из вычислительной системы и системы управления базой данных СУБД.
Под вычислительной системой будем понимать серийно выпускаемую электронно-вычислительную машину (ЭВМ) либо несколько ЭВМ, соединенных каналами связи в вычислительную сеть.
База данных предполагает централизованное управление данными, что обеспечивает ряд преимуществ:
• сокращение избыточности хранимых данных благодаря однократному хранению каждого сообщения в базе данных,
• совместное использование хранимых данных всеми пользователями ЭИС,
• стандартизацию представления данных, упрощающую проблемы эксплуатации БД и обмена данными между ЭИС,
• обеспечение процедур проверки достоверности информации и процедур ограничения доступа к данным,
• совмещение требований к использованию БД со стороны различных пользователей ЭИС.
Системой управления базой данных называется комплекс программ, обеспечивающий централизованное хранение, накопление, модификацию и выдачу данных, входящих в БД.
Предполагается, что в управлении базой данных принимает участие специальное должностное лицо - администратор базы данных.
Компоненты экономической информационной системы можно представить в виде схемы (Рис.4).
 |
|||
 |
|||
Рис. 4. Компоненты экономической информационной системы
Взаимосвязанные ресурсы и процессы экономической системы можно описать в терминах предметной области.
Предметной областью называются элементы материальной системы, информация о которых хранится и обрабатывается в ЭИС.
В качестве предметной области можно изучать не только материальные системы, но и саму ЭИС. Выделяемые в ЭИС объекты, свойства и взаимодействия служат понятийной основой для моделей создания и функционирования ИС. Такие компоненты ИС, как база данных и программное обеспечение, не являются физическими объектами, поэтому информационное отображение ИС осуществляется в метаинформацию. Метаинформацию следует представлять как информацию об информации.
Пользователей экономической информационной системы можно подразделить на пять типов:
• случайные пользователи, взаимодействие которых с ЭИС не обусловлено их служебными обязанностями,
• параметрические пользователи, которые работают с ЭИС повседневно, в соответствии с четко определенной областью деятельности, по регламентированным процедурам,
• аналитики и исследователи, информационные потребности которых непредсказуемы (в отличие от параметрических пользователей),
• прикладные программисты, которые разрабатывают программы для реализации запросов к базе данных. Эти программы используются в основном параметрическими пользователями,
• системные программисты, которые разрабатывают служебные программы, расширяющие возможности операционной системы ЭВМ и СУБД, например программы разграничения доступа к данным, проверки достоверности данных, восстановления базы данных после сбоя в работе ЭВМ, программы печати документов и т.п.
Описание хранимой и обрабатываемой информации в ЭИС делается с разной степенью детализации. Используются три уровня представления
:
1. Внешний уровень - описание информационных потребностей конечного пользователя.
2. Концептуальный уровень - описание информационных потребностей на уровне понятий ЭИС.
3. Внутренний уровень - описание способа хранения информации в памяти ЭВМ и методов доступа к ней.
Внутренний уровень наиболее близок к физической памяти ЭВМ, внешний уровень наиболее близок к пользователям, а концептуальный уровень занимает промежуточное положение.
Информационные потребности отдельного пользователя относятся лишь к небольшой части базы данных, и описание этих потребностей может не совпадать с хранимыми в ЭИС представлениями данных.
Внешнее представление может пользоваться любым аппаратом понятий. Единственное требование состоит в возможности преобразования его в концептуальное представление. Цель концептуального уровня - создать такое формальное представление о базе данных, чтобы любое внешнее представление являлось его подмножеством. В процессе интеграции внешних представлений устраняются двусмысленности и противоречия в информационных потребностях различных пользователей. Допускается много внешних описаний, каждое из которых отображается частью базы данных, и единственное концептуальное описание, представляющее всю БД.
Как известно, в естественном языке различаются правила написания текстов (синтаксис языка) и сами тексты (книги, статьи и т.д.). В обработке данных правила описания данных содержатся в моделях данных, а описание информации для конкретной ЭИС называется представлением, схемой или структурой.
Принципиальными различиями обладают три модели данных - реляционная, сетевая и иерархическая, у которых разные множества допустимых информационных конструкций.
Существующие СУБД обеспечивают реализацию возможностей этих моделей данных с теми или иными ограничениями и уточнениями, что дает повод говорить о наличии самостоятельной модели данных у каждой СУБД. Однако при создании СУБД происходит модификация модели данных исходя из удобства программной реализации системы.
Организация данных в ЭИС рассматривается с позиций той или иной модели данных, и обычно за пределами рассмотрения остаются методы представления звуковых сигналов, изображений и т. п.
Внутреннее описание данных определяет организацию данных в памяти ЭВМ и методы доступа к данным. Это наиболее детальное описание процессов обработки данных в ЭИС. Если ЭИС разработана с применением СУБД, то требуемые параметры внутреннего описания довольно немногочисленны.
В ряде случаев применение СУБД не позволяет реализовать все требования к ЭИС (например, высокое быстродействие программ). Тогда для поддержки внутреннего уровня описания системы требуется разработка уникальных программ доступа к ним.
§ 1.3. Операции над единицами информации.
Экономические показатели
Нами уже определены такие единицы информации как атрибут и СЕИ. Атрибут имеет имя и значение. Все допустимые значения атрибута образуют множество, называемое доменом. СЕИ характеризуется именем, структурой и значением. Имя СЕИ – это ее условное обозначение в процессах обработки информации. Структурой СЕИ называется вхождение одних единиц информации в состав других единиц информации.
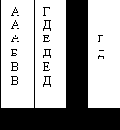
Аппарат СЕИ рассчитан на описание структуры экономических документов. Документом называют материальный носитель информации, содержащий оформленные в установленном порядке сообщения и имеющий юридическую силу. Для описания структуры СЕИ указывают после имени СЕИ список имен входящих в СЕИ атрибутов и других СЕИ и их размерность. Например, на рис.5 представлен документ со следующей схемой:
А1(2).(В, С, А2(3).(М, Н, Р))
Существует ряд операций, которые можно выполнить с СЕИ.
Выборка – операция выделения подмножества значений СЕИ, которые удовлетворяют заранее поставленным условиям выборки.
Корректировка означает выполнение одной из операций:
- добавление нового значения СЕИ;
- исключение существующего значения СЕИ;
- замена некоторого значения СЕИ на новое значение.
Декомпозиция – операция преобразования исходной СЕИ в несколько СЕИ с различными структурами. Документ А1 можно представить в виде двух документов А2(В, С) и А3(М, Н, Р).
Композиция - операция преобразования нескольких СЕИ с различными структурами в одну СЕИ. Декомпозиция и композиция являются взаимообратными операциями.
Нормализация - это операция перехода от СЕИ с произвольной структурой к СЕИ с двухуровневой структурой.
|
А1 |
В |
С |
||
|
01.03.02 |
1457 |
|||
|
М |
Н |
Р |
||
|
3412 |
2367 |
537 |
||
|
1324 |
5642 |
753 |
||
|
4587 |
4583 |
674 |
||
|
А1 |
В |
С |
||
|
02.03.02 |
1458 |
|||
|
М |
Н |
Р |
||
|
1243 |
4356 |
245 |
||
Свертка – операция преобразования СЕИ с двухуровневой структурой в СЕИ с произвольной многоуровневой структурой . Свертка нормализованной структуры может привести к исходной структуре или к другим ненормализованным документам, имеющим экономический смысл.
Экономические показатели
При анализе экономических документов необходимо разделять документ на элементарные осмысленные фрагменты, называемые показателями. Это позволяет установить смысловые взаимосвязи между различными документами, обеспечить одинаковое понимание всеми пользователями применяемых единиц информации и их единое обозначение, использовать полученные результаты для определения структуры базы данных.
Так как показатель описывает качественные и количественные характеристики, то в его состав будут входить атрибуты двух видов: атрибуты основания и атрибуты признаки. Атрибут-основание отражает количественную характеристику показателя, и в показателе он должен быть один. Атрибут-признак представляет собой качественную характеристику показателя, и их в атрибуте может быть несколько.
Вместе с тем существуют документы, не содержащие атрибутов-оснований, например, анкеты кадрового учета, сведения о структуре подразделений предприятия и т.д.
Как единица информации показатель является разновидностью СЕИ. Схематично структура показателя П представляется выражением
П(Р1,Р2,...,Рk, Q),
где Р1,Р2,...,Рk - атрибуты-признаки, Q - атрибут-основание.
Таким образом, в показателях отображаются количественные свойства объектов и процессов. Вместе с тем существуют документы, не содержащие атрибутов-оснований, например, анкеты кадрового учета, сведения о структуре подразделений предприятия и т.
д. Следовательно, не вся экономическая информация может быть представлена в форме показателей.
Минимальный набор атрибутов должен содержать:
- атрибуты, отображающие идентификаторы объектов;
- атрибуты, отображающие признак времени;
- атрибуты, отображающие некоторое количественное свойство объекта или взаимодействия.
Для определения атрибутов-признаков и атрибутов-оснований в конкретных документах используются следующие закономерности:
1. Если значение атрибута является исходным данным или результатом арифметической операций - это основание.
2. Если значение текстовое - это признак.
3. Если атрибут обозначает предмет - это признак.
4. Если атрибут в некотором показателе является признаком (основанием), - он будет играть эту роль и в других показателях.
5. Если показатели описывают сходные процессы - их призначные части совпадают.
6. Если основание показателя вычисляется по значениям других оснований, то набор признаков такого показателя есть объединение признаков, связанных с этими основаниями.
Например, документ содержит следующие атрибуты:
Дата Цена
Поставщик Количество по документу
Магазин Количество принято
Товар Сумма
Атрибутами-основаниями являются: Цена, Количество, Сумма, так как они описывают количественные характеристики документа. Таким образом, и показателей в документе будет четыре, по числу атрибутов-оснований. Теперь необходимо выяснить какие атрибуты-признаки соответствуют каждому атрибуту-основанию. Для атрибута Количество по документу необходимыми признаками будут: Дата, Поставщик, Магазин, Товар. Для атрибута Количество принято , исходя из закономерности №5, атрибуты- признаки будут такие же, как и для атрибута Количество по документу.
Если цены постоянные и не зависят ни от поставщика, ни от даты поступления, то атрибут Цена будет зависеть только от атрибута Товар. Так как Сумма является показателем, вычисляемым по формуле, то его призначная часть определяется на основании закономерности №6. Показатели будут представлены следующими схемами:
П1(Дата, Поставщик, Магазин, Товар, Количество по документу),
П2(Дата, Поставщик, Магазин, Товар, Количество принято),
П3(Товар, Цена),
П4(Дата, Поставщик, Магазин, Товар, Сумма).
Из четырех показателей три имеют одинаковую призначную часть, следовательно, их можно объединить в один файл. В результате получим в базе данных два файла: первый файл – атрибуты Товар, Цена. Второй файл – атрибуты Дата, Поставщик, Магазин, Товар, Количество по документу, Количество принято, Сумма.
Существует аналогия между экономическими показателями и переменными с индексами, которые рассматриваются, например, в линейной алгебре. Так, показатель П3(Товар, Цена) соответствует величине Сi, где С – цена i-того товара.
Остальным показателям соответствуют такие переменные с индексами, как
для П1 G(i, j, m, n)
для П2 H(i, j, m, n)
для П4 S(i, j, m, n),
где:
j – магазин,
m – поставщик
n - дата
Критерием качества создания базы данных может служить минимальная избыточность хранимой информации. Обычно минимальная избыточность выражается принципом: каждое сообщение хранится в БД один раз. Использование аппарата экономических показателей позволяет создать структуру БД с минимальной избыточностью, если сначала представить все сведения, циркулирующие в ЭИС, в виде показателей, а потом объединить атрибуты родственных показателей по принципу: в один файл включается группа экономических показателей с одинаковым составом атрибутов-признаков.
Вопросы и задания
1. Приведите классификацию ЭИС и их отличительные черты.
2. Перечислите компоненты экономических информационных систем.
3. Назовите операции, выполняемые над СЕИ.
4. Каково назначение экономических показателей?
5. Представьте результат нормализации СЕИ со следующей структурой:
Н(2).(М(3).(м1, м2, м3, м4), Л(4).(л1, л2))
6. Определите экономические показатели, атрибутный состав и количество файлов для следующего списка атрибутов:
а)
Цех Год План выпуска на месяц
Участок Код детали План выпуска на квартал
Месяц Расценка
б)
Дата Код детали Расценка
Участок Разряд Сумма
Таб № рабочего Принято деталей
в)
Кинотеатр Фильм Режиссер
Число мест Дата Число проданных мест
Выручка от фильма
7. Приведите примеры экономических информационных систем, классифицируемых по функциональным признакам.
8. Что такое предметная область?
9. Каков минимальный набор атрибутов показателя?
10. Назовите критерий качества создания базы данных?
ГЛАВА 2. МОДЕЛИ ДАННЫХ
§ 2.1. Реляционная модель данных
§ 2.1.1. Основные понятия реляционной модели данных
Каждой модели данных соответствует указание множества допустимых информационных конструкций, множества допустимых операций над данными и множества ограничений для хранимых значений данных.
Классификация информационных конструкций тесно связана с областью их использования в ЭИС:
- Объекты для технологии баз данных – отношения, веерные отношения, иерархическая БД;
- Объекты для технологии искусственного интеллекта – предикаты, фреймы и семантические сети;
- Объекты для технологии мультимедиа – тексты, графические изображения, видеофрагменты.
Принципиальными различиями обладают следующие модели данных:
реляционная;
сетевая;
иерархическая.
Реляционные модели данных приобрели наибольшую популярность и практически все современные СУБД ориентированы именно на такое представление данных.
Реляционная модель характеризуется следующими компонентами:
1. Информационная конструкция – отношение с двухуровневой структурой.
2. Допустимые операции – проекция, выборка, соединение, объединение, пересечение, вычитание, деление.
3. Ограничения – функциональные зависимости между атрибутами отношения.
Традиционно в реляционных системах таблицу называют отношением, строку таблицы называют кортежем. Количество кортежей в таблице называется кардинальным числом, а количество атрибутов степенью.
Для отношения предусматривается уникальный идентификатор, то есть один или несколько атрибутов, значения которых в одно и то же время не бывают одинаковыми – идентификатор называется первичным ключом.
Домен – это множество допустимых однородных значений для того или иного атрибута. Таким образом, домен можно рассматривать как именованное множество данных, причем составные части этого множества являются логически неделимыми единицами (в качестве домена могут, например, выступать фамилии сотрудников учреждения, однако не все фамилии могут присутствовать в таблице).
Отношение содержит две части – заголовок и, собственно, содержательную часть. Заголовок содержит конечное множество атрибутов, а содержательная часть (тело отношения) – множество пар имени атрибута и его значения.
Отношения имеют ряд основных свойств, а именно:
- в самом общем случае в отношении не бывает двух одинаковых кортежей. Это следует из самого определения отношения, действительно, поскольку в отношении имеет место первичный ключ, то одинаковые кортежи исключены.
- в отношении без потери информации можно с успехом расположить кортежи в любом порядке.
- атрибуты не упорядочены слева направо и их можно располагать в любом порядке, при этом целостность (единство) данных не нарушится.
- значения атрибутов состоят из логически неделимых единиц - это свойство есть следствие того, что значения берутся из доменов.
Иначе, можно сказать, что отношения не содержат групп повторения, то есть являются нормализованными (об этом еще будем говорить).
Предположим, что некоторому классу объектов материального мира Р ставится в соответствие множество атрибутов А1, А2,…, Аn. Отдельный объект класса Р описывается строкой величин (а1, а2,…, аn), где аi – значение атрибута Аi. Строка (а1, а2, …,аn) будет являться кортежем.
Выражение (а1,а2, …, аn) называется схемой отношения Р. Каждое отношение представляет собой состояние класса объектов в некоторый момент времени. Следовательно, одной схеме отношения в разные моменты времени могут соответствовать разные отношения.
Схема реляционной базы данных содержит следующие компоненты
S(rel) = < A, R, Dom, Rel, V(s)>,
где A – множество имен атрибутов,
R – множество имен отношений,
Dom – вхождение атрибутов в домены,
Rel – вхождения атрибутов в отношения,
V(s) – множество ограничений (в том числе функциональных зависимостей).
Описание процессов обработки отношений может быть выполнено двумя способами:
- указанием перечня операций, выполнение которых приводит к требуемому результату (процедурный подход),
- описанием свойств, которым должно удовлетворять результирующее отношение (декларативный подход).
Проводимые далее операции над отношениями ориентированы на процедурное описание процессов обработки данных.
§ 2.1.2.Реляционная алгебра
Формальной основой реляционной модели является реляционная алгебра, рассматривающая специальные операторы над отношениями на основе теории множеств и реляционное исчисление, базирующееся на математической логике.
Основных операторов в реляционной алгебре восемь и схематически их можно представить так, как это показано на рис. 6










Пересечение Вычитание Произведение
|
| |||||||||||
 |
|||||||||||
 |
 |
||||||||||
 |
 |
|
|||||||||
Соединение Деление
 |
Основная идея реляционной алгебры состоит в том, что средства манипулирования отношениями, рассматриваемыми как множества, основаны на традиционных множественных операциях, дополненных некоторыми специфическими операциями для БД.
Существует много подходов к определению реляционной алгебры, которые различаются набором операций и способами их интерпретации, но в принципе все они более или менее равносильны. Опишем вариант алгебры, предложенный Коддом. В этом варианте набор алгебраических операций состоит из восьми основных.
Проекция отношения – при осуществлении проекции отношения на заданный набор его атрибутов будет получено отношение, кортежи которого взяты из соответствующих кортежей первоначального отношения. Алгебраическая запись проекции имеет вид:
Т = R[X],
где R – исходное отношение,
T – результирующее отношение,
X – список атрибутов в структуре отношения Т (условие проекции).
Пример
Рассмотрим два отношения:
Т1, содержащее сведения о заявке на изделия и Т2, в котором указаны цены на изделия и комплектующие.
|
Т1 |
||||
|
Отправитель |
Получатель |
Адрес получателя |
Изделие |
Количество на месяц |
|
Прибор |
Полет |
Русская, 86 |
ХТ - 12 |
1000 |
|
Дальтехника |
Скала |
Луговая,91 |
АМ - 18 |
350 |
|
Прибор |
Сокол |
Карбышева, 86 |
ХТ - 12 |
800 |
|
Звезда |
Луч |
Калинина,80 |
ЛН - 15 |
500 |
|
Т2 |
||
|
Изделие |
Цена |
Комплектующие |
|
ХТ - 12 |
100 |
АСК |
|
АМ - 18 |
150 |
ТРН |
|
ЛН - 15 |
130 |
НЕК |
Х1 = Т1[Получатель, адрес получателя]
и имеет вид
|
Х1 |
|
|
Получатель |
Адрес получателя |
|
Полет |
Русская, 86 |
|
Скала |
Луговая,52 |
|
Сокол |
Карбышева, 16 |
|
Луч |
Калинина, 80 |
Выборка отношения – результатом выборки отношения по некоторому условию является отношение, которое включает только те кортежи первоначального отношения, которые удовлетворяют этому условию. Существуют две простейшие разновидности условия выборки:
1. Условие вида Имя_атрибута <знак сравнения > Значение, где допускаются знаки сравнения =, #, >, =>, <, <=. Например, Количество < 20.
2. Условие вида Имя_атрибута 1<знак сравнения > Имя атрибута 2. Например, Факт > План.
Алгебраическая запись выборки имеет вид
T = R[p],
где R – исходное отношение,
T – результирующее отношение,
р – условие выборки.
Например, X2 = T1[Количество в месяц > 800].
|
Х2 |
||||
|
Отправитель |
Получатель |
Адрес получателя |
Изделие |
Количество на месяц |
|
Прибор |
Полет |
Русская, 86 |
ХТ - 12 |
1000 |
|
Прибор |
Сокол |
Карбышева, 86 |
ХТ - 12 |
800 |
Х3 = U(R1, R2).
В качестве результата операции пересечения двух отношений получается отношение, включающее все кортежи, входящие в оба первоначальные отношения,
Х4 = I(R1, R2).
Отношение, являющееся разностью двух отношений, включает все кортежи, входящие в первое отношение и одновременно такие, что ни один из них не входит в отношение являющееся вторым,
Х5 = M(R1, R2).
При соединении двух отношений по некоторому условию образуется результирующее отношение, кортежи которого являются сочетанием кортежей первого и второго отношений, удовлетворяющим этому условию. Условие соединения имеет вид:
Имя_ атрибута_1 <знак сравнения > Имя_атрибута_2,
где Имя_ атрибута_1 находится в одном исходном отношении, Имя_ атрибута_2 в другом.
Операция имеет следующее обозначение
Х6 = R1[p]R2,
где p – условие соединения.
Наиболее важный частный случай соединения называется натуральным соединение и имеет следующие особенности:
- знаком сравнения в условии соединения является =;
- Имя_ атрибута_1 и Имя_атрибута_2 должны совпадать, а точнее содержать пересечение списков атрибутов исходных отношений;
- список атрибутов результирующего отношения образуется в результате объединения списков атрибутов исходных отношений.
Обозначение натурального соединения не содержит условия соединения и имеет вид
Х7 = R1*R2.
Операция натурального соединения имеет ряд свойств, например коммутативность и ассоциативность.
Свойство коммутативности означает, что операции
X8 = R*S и X9 = S*R
порождают одно и то же отношение.
Свойство ассоциативности означает, что операция X10 = (R*S)*Т и операция X11 = R*(S*Т) дают одинаковый результат.
Описание операции деления начнем с примера.
Пусть существует отношение Х12, в котором для каждого специалиста указано программное средство, которым он владеет. Определить специалистов, которые владеют MS Excel и Project-Expert.
|
Х12 |
|
|
ФИО |
Программное средство |
|
Иванов |
MS Excel |
|
Иванов |
Project-Expert |
|
Петров |
MS Word |
|
Петров |
MS Excel |
|
Петров |
MS Access |
|
Сидоров |
MS Word |
|
Сидоров |
MS Excel |
|
Сидоров |
Project-Expert |
im B(a) = {b1, b2, …, bk},
где im – знак операции «образ»,
а – значение, образ которого вычисляется,
B – имя атрибута для образа значения а
b1, b2, …, bk – значения атрибута В.
Задача решается путем вычисления образа значений MS Excel и Project-Expert и последующего пересечения найденных образов.
im ФИО(«MS Excel») = {«Иванов», «Петров», «Сидоров»}
im ФИО(«Project-Expert») = {«Иванов», «Сидоров»}
im ФИО(«MS Excel») ? im ФИО(«Project-Expert») = {«Иванов», «Сидоров»}
Таким образом, выполнена операция деления исходного отношения на отношение, которое имеет вид:
|
Х13 |
|
MS Excel |
|
Project-Expert |
|
Х14 |
|
Иванов |
|
Сидоров |
Q = D(W, V), где
D – знак операции деления.
§ 2.1.3. Операции над отношениями с применением
конструкций языка SQL
Structured Query Language – язык структурированных запросов – используется при:
- формировании запросов к реляционным базам данных, таким как MS Access;
- обновлении реляционных баз данных;
- управлении реляционными базами данных.
Результаты выполнения запросов можно обрабатывать с помощью специальных групповых функций, таких как максимум, минимум, среднее значение и т.д.
Список операторов, предикатов и директив
с соответствующими параметрами
|
Ключевое слово |
Перевод |
|
Select <список полей> |
Выбрать |
|
From <имена таблиц> |
Из |
|
Where условие поиска |
При |
|
In <имя внешней базы данных> |
В |
|
Inner join |
Объединяя |
|
Group by <список полей> |
Группируя по |
|
Having <условие поиска> |
Имеющие |
|
Order by <список полей> |
Упорядочивая по |
|
As <псевдонимы> |
Как |
|
All, distinct |
Все, различные |
|
Distinctrow, top |
Различные ряды, первые |
§ составляющие один запрос директивы не должны быть разделены символами «конец строки». Для принудительного перехода можно использовать комбинацию клавиш Ctrl+Enter;
§ обязательными компонентами запроса являются Select и From;
§ Select является первым в определении запроса;
§ при указании более, чем одного поля , их имена отделяются запятыми;
§ перечислять имена полей необходимо в той последовательности, в которой они будут показаны в запросе;
§ если имя поля содержит знак пробела или другой разделитель, имя следует заключить в квадратные скобки;
§ если в запросе обрабатывается несколько таблиц, то во избежание неопределенности в списках полей рекомендуется приводить полную спецификацию поля, т.е. <имя_таблицы>, <имя_поля>;
§ каждый запрос заканчивается ;
Оператор SELECT
SELECT Клиенты.Фирма
FROM Клиенты, [Заинтересованные лица]
WHERE Клиенты.Фирма = [Заинтересованные лица].Фирма;
Выборка будет содержать все фирмы, которые присутствуют как в таблице «Заинтересованные лица», так и в таблице «Клиенты».
Директива FROM
SELECT Клиенты.*
FROM Клиенты;
С помощью * из таблицы можно выбрать все поля.
Директива WHERE
Является необязательной, но если присутствует, то должна следовать за директивой FROM. Access выберет записи данных, которые соответствуют определенным в WHERE условиям отбора.
Если WHERE отсутствует, то будут выбраны все записи данных.
Параметр IN
Данный параметр используется при работе с базами данных других форматов, с которыми может работать Access, а так же для отбора данных из неактивной базы Access.
SELECT Клиенты.Фирма
FROM Клиенты, [Заинтересованные лица]
IN C:\DBASE\DATA\CLEENTS «DBASEIV;»
WHERE Клиенты.Фирма = [Заинтересованные лица].Фирма;
С помощью данного параметра можно сформировать только одну связь к внешней БД. Для указания формата этой БД необходимо после формата поставить ; и все выражение взять в кавычки.
Предикаты
1. ALL
SELECT ALL Фамилия, Имя, Отчество
FROM Клиенты;
Access выберет перечисленные поля из всех записей данных в таблице Клиенты. Предикат представляет собой дополнительный фильтр. Если предикаты не используются, то по умолчанию считается, что применен предикат ALL. Следующие два примера позволяют выполнить одинаковые выборки.
|
SELECT ALL * FROM Клиенты; |
SELECT * FROM Клиенты; |
SELECT DISTINCT Клиенты.Фирма
FROM Клиенты, Заинтересованные лица
WHERE Клиенты.Фирма = Заинтересованные лица.Фирма;
Директива WHERE задает условия отбора, в соответствии с которыми в выборку включаются те фирмы, которые присутствуют как в таблице Клиенты, так и в таблице Заинтересованные лица.
Предикат DISTINCT используется в том случае, если нужно включить в выборку только уникальные значения для выбираемых полей. Предикат DISTINCT приводит к отбрасыванию дублируемых значений поля «Фирма».
DISTINCTROW
SELECT DISTINCTROW [Название фирмы]
FROM Клиенты INNER JOIN Заказы
ON Клиенты.[Код клиента] = Заказы.[Код клиента]
ORDER BY [Название фирмы];
Предикат DISTINCTROW используется, когда следует пропустить данные, представляющие собой полностью дублирующие записи в выборке, но не дублирование значений отдельных полей. Приведен пример запроса для составления списка фирм, которые сделали хотя бы один заказ.
Предикат TOP
Используется для включения в выборку определенного числа записей, расположенных в начале или в конце группы записей, отобранных с помощью критерия отбора WHERE, упорядоченных с помощью директивы ORDER BY.
Предположим, что нужно отобрать 25 лучших студентов выпуска 2001 года:
SELECT TOP 25[Фамилия], [Имя], [Отчество]
FROM Студенты
WHERE [Год выпуска] = 2001
ODER BY [Средний балл] DESC;
Можно использовать ключевое слово для того, чтобы включить в выборку определенный процент из верхней или нижней части диапазона, отсортированного с помощью директивы ORDER BY.
SELECT TOP 10 PERCENT [Фамилия], [Имя], [Отчество]
FROM Студенты
WHERE [Год выпуска] = 2001
ORDER BY [Средний балл] DESC;
Используемое число в предикате TOP должно быть целым без знака.
Операция объединения INNER JOIN
Операция формирует связь эквивалентности, являясь частью параметра FROM Такая связь является наиболее употребительным типом объединения. Объединение производится при условии равенства содержимого полей, приведенных после ключевого слова ON в записях таблиц, указанных в операции INNER JOIN. Записи их двух таблиц объединяются при обнаружении совпадающих значений в указанных полях. Такое объединение записей используется наиболее часто.
ТАБЛИЦА 1 INNER JOIN ТАБЛИЦА 2
ON ТАБЛИЦА 1.Поле А = ТАБЛИЦА 2.Поле В
В данном случае устанавливается связь между ТАБЛИЦА 1 и ТАБЛИЦА 2. В выходной набор будут включены записи из этих таблиц при условии равенства содержимого: ТАБЛИЦА 1.Поле А = ТАБЛИЦА 2.Поле В.
В операции могут участвовать два числовых поля любого типа или , если поля не числовые, поля одинакового типа и размера.
Директива GROUP BY
При использовании директивы GROUP BY все записи, содержащие в заданном поле идентичные значения, объединяются в один элемент выходного набора. В нашем примере повторяющиеся имена фирм будут включены в выходной набор только один раз. Используя параметр GROUP BY, необходимо учитывать, что этот параметр не является обязательным, а является уточняющим при использовании параметра FROM и WHERE.
SELECT [Название товара], Sum([Стоимость товара])
FROM Товары
GROUP BY [Название товара];
Директива HAVIHG
Эта директива используется для фильтрации записей после группирования только в случае использования в запросе директивы GROUP BY.
Отличие WHERE и HAVING
Директива WHERE определяет, какие записи данных должны участвовать в группировании, т. е. фильтрует записи до группировки. HAVING oпределяет, какие из получившихся в результате группировки записи будут включены в результирующую выборку, т. е. фильтрует записи после группирования.
SELECT Отдел, Count([Отдел])
FROM Сотрудники
GROUP BYОтдел
HAVING Count(Отдел)>50;
В выборку будут включены отделы, в которых число сотрудников более 50 человек.
Директива ORDER BY
Директива определяет список полей и порядок сортировки записей данных, включенных в выборку. Директива является обязательной только при использовании предиката TOP. В других случаях необязательна. По умолчанию используется сортировка по возрастанию. Этому порядку сортировки соответствует ключевое слово ASC. Ключевое слово DESC задает сортировку по убыванию.
ORDER BY Является последней директивой в запросе.
Порядок перечисления полей задает иерархию сортировки. Прежде всего записи в выборке сортируются по первому указанному в ORDER BY полю, затем записи с совпадающими значениями первого поля сортируются по второму по второму и т. д.
Групповые функции
С помощью групповых функций можно получить ряд обобщающей статистической информации. К групповым функциям относятся следующие функции:
|
Обозначение |
Функция |
Назначение |
|
Sum |
Сумма |
Вычисляет сумму сгруппированных значений |
|
Avg |
Среднее |
Вычисляет среднее значение сгруппированных значений |
|
Min |
Минимум |
Находит наименьшее из сгруппированных значений |
|
Max |
Максимум |
Находит наибольшее из сгруппированных значений |
|
Count |
Счетчик |
Находит количество сгруппированных записей |
|
Stdev |
Стандартное отклонение |
Находит стандартное отклонение для сгруппированных значений |
|
Var |
Дисперсия |
Вычисляет дисперсию для сгруппированных значений |
|
First |
Первое |
Возвращает первое из сгруппированных значений |
|
Last |
Последнее |
Возвращает последнее из сгруппированных значений |
SELECT SUM ([Цена]* [Количество]) AS [Общая стоимость]
FROM [Заказы]
WHERE [Город] = Санкт-Петербург;
В этом примере функция служит для вычисления общей стоимости всех заказов по Санкт-Петербургу из таблицы заказов. В качестве аргумента используется произведение значений полей цены и количества.
SELECT AVG([Цена])
FROM [Заказы]
WHERE [Цена] > 1000000;
В этом примере среднее значение вычисляется как сумма всех значений, деленная на их количество.
SELECT MIN ([Цена])
FROM [Заказы]
WHERE [Город] = Санкт-Петербург;
В этом запросе определяется минимальная цена заказов по Санкт-Петербургу.
§ 2.1.4. Нормализация отношений
Основной задачей проектировщика базы данных является определение количества отношений и их атрибутного состава. Рациональные варианты должны учитывать следующие требования:
- множество отношений должно обеспечивать минимальную избыточность представления информации;
- корректировка отношений не должна приводить к двусмысленности или потере информации;
- перестройка набора отношений при добавлении в базу данных новых атрибутов должна быть минимальной.
Одним из наиболее изученных способов преобразования отношений является нормализация отношений, т.е. декомпозиция отношения, находящегося в предыдущей нормальной форме в два и более отношений, удовлетворяющих требованиям следующей нормальной формы.
В теории реляционной БД обычно выделяются следующая последовательность нормальных форм:
§ первая нормальная форма (1НФ);
§ вторая нормальная форма (2НФ);
§ третья нормальная форма (3НФ);
§ нормальная форма Бойса-Кодда (НФБК);
§ четвертая нормальная форма (4НФ);
§ пятая нормальная форма, или нормальная форма проекции соединения (5НФ или НФПС).
Каждая нормальная форма более высокого порядка является более выгодной с точки зрения реляционных БД, чем предыдущая. При этом необходимо заметить тот факт, что если некоторая БД находится во 2НФ, то не исключено, что ее часть уже находится в 3НФ, внутри которой может находиться часть в НФБК и т.д.
Основные свойства нормальных форм:
§ каждая следующая нормальная форма в некотором смысле лучше предыдущей;
§ при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
Каждой нормальной форме соответствует некоторый набор ограничений. Отношение, находящееся в некоторой нормальной форме должно удовлетворять свойственному этой форме набору ограничений. Требования 1НФ являются базовыми в классической реляционной модели данных.
Отношение будет находиться в первой нормальной форме при условии, что содержит только логически неделимые значения. Такие значения называются скалярными. Отношение в первой нормальной форме – это обычное отношение с двухуровневой структурой. Отношение в 1НФ обладает избыточностью информации.
Функциональные зависимости и ключи
Функциональные зависимости определяются для атрибутов, находящихся в одном и том же отношении, удовлетворяющем первой нормальной форме.
В отношении Т(А,В) атрибут А функционально определяет атрибут В, если в любой момент времени каждому значению А соответствует единственное значение В. Обозначается А à В. Отсутствие функциональной зависимости обозначается А -/à В
Рассмотрим пример с атрибутами ФИО и Адрес.
|
Т |
|
|
ФИО |
Адрес |
|
Иванов И.И. |
Некрасова, 96-15 |
|
Иванова А.А. |
Некрасова, 96-15 |
|
Петров Н.Н. |
Океанский пр., 102-43 |
Одновременное соблюдение двух зависимостей вида А à В и В à А называется взаимно-однозначным соответствием и обозначается А - В.
В качестве примера можно рассмотреть отношение Т2 .
|
Т2 |
|
|
Предприятие |
Расчетный счет |
|
ОАО «Зенит» |
123069798 |
|
Завод «Спектр» |
456274895 |
|
Магазин «Заря» |
572947589 |
|
ЧП «ИвановА.К.» |
4867205968 |
Можно утверждать, что у каждого предприятия единственный номер расчетного счета, и каждый расчетный счет принадлежит единственному предприятию. Это доказывает справедливость функциональных зависимостей Магазин -> Расч и Расч -> Магазин, т.е. Магазин <-> Расч.
Наконец, самыми распространенными являются случаи отсутствия функциональных зависимостей, например,
ФИО -/-> Дисциплина и Дисциплина -/-> ФИО
в отношении, описывающем экзамены студентов. Здесь каждый студент сдает экзамены по нескольким дисциплинам, и по каждой дисциплине экзамен сдается многими студентами.
Таким образом, для атрибутов А и В некоторого отношения возможны следующие ситуации:
• отсутствие функциональной зависимости,
• наличие функциональных зависимостей А -> В (или В -> А), но не обе зависимости вместе,
• наличие взаимно-однозначного соответствия А<->В.
Существуют функциональные зависимости между тремя и более атрибутами. Группа атрибутов - А, В, С - функционально определяет атрибут D в отношении T(A, B, C, D,....), если каждому сочетанию значений <а, b, с> соответствует единственное значение d (а - значение A, b - значение В, с - значение С, d - значение D). Наличие такой функциональной зависимости будем обозначать А,В,С -> D.
Функциональные зависимости позволяют определить такие важные понятия как ключи отношения – вероятные, первичные, вторичные. Вероятный ключ отношения – это такое множество атрибутов, в котором каждое сочетание их значений встречается только в одной строке отношения, и никакое другое подмножество атрибутов этим свойством не обладает. В отношении может быть несколько вероятных ключей.
Важность вероятных ключей при обработке данных определяется тем, что выборка по известному значению вероятного ключа дает в результате одну строку отношения либо ни одной. На практике атрибуты вероятного ключа отношения связываются со свойствами тех объектов и событий, информация о которых хранится в отношении. Если в результате корректировки отношения изменились имена атрибутов, образующих ключ, то это свидетельствует о серьезном искажении информации.
Следовательно, систематическая проверка свойств вероятного ключа позволяет следить за достоверностью информации в отношении.
Если в отношении присутствует несколько вероятных ключей, то очень трудно одновременно следить за ними и обычно выбирают один из них в качестве основного (первичного).
Первичным ключом отношения называется такой вероятный ключ, по значениям которого производится контроль достоверности информации в отношении. Как правило, экономические документы имеют один первичный ключ. Первичный ключ часто называется просто ключ.
Нахождение первичного ключа затрудняется большим количеством информации и неизвестностью сразу всех отношений, поэтому первичный ключ отношения определяется по известным функциональным зависимостям.
Каждое значение первичного ключа встречается только в одной строке отношения. Значение любого атрибута в этой строке также единственное. Если через К обозначить атрибуты первичного ключа в отношении F(A,B,C,..., I), то справедливы следующие функциональные зависимости К-> А, К-> В, К-> С,... ,
К -> I. Набор атрибутов первичного ключа функционально определяет любой атрибут отношения. Обратное также верно: если найдена группа атрибутов, которая функционально определяет все атрибуты отношения по отдельности, и эту группу нельзя сократить, то найден первичный ключ отношения.
Функциональные зависимости могут быть выражены с помощью ряда теорем. Эти теоремы позволяют получать новые зависимости из исходного множества зависимостей. Приведем шесть теорем, хотя на их основе могут быть получены и другие теоремы.
Теорема 1
А,В -> А и А,В -> В.
Доказательство основано на том, что в строке <а, b> для атрибутов А и В значение а (как и значение b) присутствует один раз.
Теорема 2
А -> В и А -> С тогда и только тогда, когда А -> ВС.
Для доказательства рассмотрим произвольное значение а атрибута А. Если А-> В иА-> С, то im В(а) и im С(а) содержат по одному элементу. Предположим, что зависимость А -> ВС неверна и im ВС(а) состоит из двух или более элементов.
Тогда либо im В(а), либо im С(а) должны содержать более одного элемента. Полученное противоречие доказывает зависимость А -> ВС.
Теорема 3
Если А - > В и В - > С, то А - > С
Теорема доказывается от противного.
Теорема 4
Если А- > В, то АС - > В (С – произвольно)
Доказательство основано на теореме 1 и 3.
Теорема 5
Если А - > В, то АС - > ВС (С – произвольно).
Доказательство основано на теоремах 4, 1, 2.
Теорема 6
Если А -> В и ВС - > D, то АС -> D.
Доказательство основано на теоремах 5 и 3.
Для некоторого множества функциональных зависимостей F введем множество F~, называемое покрытием. Покрытие F~ содержит все функциональные зависимости, которые можно получить из множества F в результате применения теорем 1- 6 (включая и содержимое F). Одно и то же покрытие F~ может быть получено из различных множеств функциональных зависимостей. Среди таких множеств выделим множество с минимальным числом зависимостей и назовем его минимальным покрытием (базисом) множества зависимостей F. Иначе можно сказать, что минимальным покрытием называется множество функциональных зависимостей, из которого удалены все зависимости, являющиеся следствиями оставшихся зависимостей и теорем 1 - 6.
Вторая и третья нормальные формы отношений
Отношение имеет вторую нормальную форму
(2НФ), если оно соответствует 1НФ и не содержит неполных функциональных зависимостей. Неполная функциональная зависимость - это две зависимости:
• вероятный ключ отношения функционально определяет некоторый неключевой атрибут,
• часть вероятного ключа функционально определяет этот же неключевой атрибут.
Например:
Имеется отношение:
|
Т |
|||
|
Наименование института |
Мероприятие |
Выделено (тыс.руб.) |
Потрачено (тыс. руб.) |
|
Институт менеджмента и бизнеса |
Конференция |
100 |
95 |
|
Институт математики и компьютерных наук |
Встреча выпускников с работодателями |
15 |
15 |
|
Институт международных отношений |
Конференция |
100 |
90 |
|
Институт менеджмента и бизнеса |
Встреча с работодателями |
15 |
12 |
|
Институт математики и компьютерных наук |
Конференция |
100 |
100 |
Функциональные зависимости отношения Т:
(1) Институт, Мероприятие à Потрачено
(2) Мероприятие à Выделено
(3) Организация, мероприятие à Выделено
(4) Организация, мероприятие à Организация
(5) Организация, Мероприятие à Мероприятие
Зависимости (2) и (3) вместе образуют неполную функциональную зависимость, так как вероятным ключом отношения Т являются атрибуты Организация и Мероприятие. Отношение Т находится в первой нормальной форме. Избыточность показана тем, что на одинаковые мероприятия выделено одинаковое количество денег, и эта информация постоянно повторяется. Устранение указанной избыточности выполняется путем создания двух отношений:
Т1 = Т[Институт, Мероприятие, Потрачено],
Т2 = Т[Мероприятие, Выделено].
|
Т1 |
Т2 |
||||
|
Наименование института |
Мероприятие |
Потрачено (тыс.руб.) |
Мероприятие |
Выделено (тыс.руб.) |
|
|
Институт менеджмента и бизнеса |
Конференция |
95 |
Конференция |
100 |
|
|
Институт математики и компьютерных наук |
Конференция |
100 |
Встреча выпускников с работодате-лями |
15 |
|
|
Институт международных отношений |
Конференция |
90 |
|||
|
Институт менеджмента и бизнеса |
Встреча выпускников с работодателями |
12 |
|||
|
Институт математики и компьютерных наук |
Встреча выпускников с работодателями |
15 |
Отношение соответствует третьей нормальной форме (3НФ), если оно соответствует 2НФ и среди его атрибутов отсутствуют транзитивные функциональные зависимости. Транзитивная функциональная зависимость – это две зависимости:
§ вероятный ключ отношения функционально определяет неключевой атрибут,
§ этот неключевой атрибут функционально определяет другой неключевой атрибут.
Например, имеется отношение Т3:
|
Т3 |
||
|
Название предмета |
ФИО преподавателя |
Кафедра |
|
ТОИСИТ |
Петров П.Г. |
ИСЭ |
|
ТСиСА |
Петров П.Г. |
ИСЭ |
|
Информатика |
Иванова И.М. |
ИСЭ |
|
ТЭИС |
Иванова И.М. |
ИСЭ |
Функциональные зависимости отношения:
(1) Предмет à Преподаватель
(2) Преподаватель à Кафедра
(3) Предмет à Кафедра.
Так как ключевым атрибутом является Предмет, то на основании приведенных функциональных зависимостей можно сделать вывод, что отношение находится во второй нормальной форме, и в нем присутствуют транзитивные функциональные зависимости. Преобразуем отношение Т3 в отношения Т4 и Т5.
Т4 = Т3[Предмет, Преподаватель],
Т5 = Т3[Преподаватель, Кафедра].
Отношения T4, T5 получились двухатрибутными, поэтому нарушение требований ЗНФ в них невозможно.
База данных находится в ЗНФ, если все ее отношения находятся в ЗНФ.
Приведенные примеры показывают, что отношения, в которых соблюдается одна ФЗ либо ни одной, будут соответствовать условиям 2НФ и ЗНФ, так как неполная и транзитивная ФЗ представляют собой две зависимости. На этом принципе основан алгоритм получения отношений в ЗНФ.
Исходными данными для алгоритма служит некоторый список атрибутов, охватывающий одно отношение, базу данных или ее часть.
Алгоритм получения отношений в ЗНФ обладает следующими свойствами:
- сохраняет все первоначальные функциональные зависимости, т.е. зависимость, справедливая в R, справедлива и в одном из производных отношений. Это гарантирует получение осмысленных отношений с легко интерпретируемой структурой,
- обеспечивает соединение без потерь, т.е. значения исходного отношения R могут быть восстановлены из проекций отношения R с помощью операции соединения,
- результат декомпозиции в ЗНФ обычно содержит меньше значений атрибутов, чем исходное отношение R (происходит уменьшение избыточности).
Алгоритм нормализации (к ЗНФ)
1. Получить исходное множество функциональных зависимостей для атрибутов рассматриваемой БД.
Если исходные функциональные зависимости не удается определить путем анализа смысловых характеристик атрибутов, приходится использовать перечисление и отбраковку допустимых вариантов функциональных зависимостей.
Рассматриваются все сочетания по два атрибута, и в каждом случае доказывается или отвергается функциональная зависимость. Затем рассматриваются сочетания:
• по три атрибута, где первые два могут функционально определять третий,
• по четыре атрибута, где первые три могут функционально определять четвертый и т.д.
Применение теорем о функциональных зависимостях позволяет сократить количество рассматриваемых вариантов. Практически перечисление вариантов заканчивается, когда сочетания атрибутов станут содержать первичный ключ.
2. Получить минимальное покрытие множества функциональных зависимостей. В минимальном покрытии должны отсутствовать зависимости, которые являются следствием оставшихся зависимостей по теоремам 1-6. В частности, требуется объединить функциональные зависимости с одинаковой левой частью в одну зависимость. Обозначим полученное минимальное покрытие функциональных зависимостей через
F={fl,...,fi,...,fk}.
3. .Определить первичный ключ отношения.
4. Для каждой функциональной зависимости fk создать проекцию исходного отношения Ri = R(Xi], где Xi - объединение атрибутов из левой и правой частей fi.
5. Если первичный ключ исходного отношения не вошел полностью ни в одну проекцию, то создать отдельное отношение из атрибутов ключа.
Вычислительная сложность каждого этапа приведения отношений к ЗНФ различна, но наиболее длительным является получение исходного списка функциональных зависимостей. Количество проверяемых ФЗ является экспоненциальной функцией от количества рассматриваемых атрибутов.
Хотя на основе функциональных зависимостей можно установить более сильную нормальную форму Бойса-Кодда (БКНФ), практически она применяется редко. Во-первых, база данных в БКНФ не всегда существует, во-вторых, ее отличие от ЗНФ обычно связано с наличием нескольких ключей в отношении, что в экономических приложениях встречается исключительно редко.
§ 2.1.5. Ациклические базы данных
Ряд ограничений в предметной области и БД не может быть описан с помощью функциональных зависимостей, что приводит к необходимости рассмотрения новых типов зависимостей - многозначных и взаимных.
В отношении R(A, B ,C) существует многозначная зависимость (МЗ)
А -> -> В, если для любого а, являющегося значением атрибута А im(BC)a = im(B)a ° im(C)a, где ° - знак декартова произведения множеств.
Положение атрибутов В и С равноценно, поэтому одновременно справедливо А -> -> С, т.е. многозначные зависимости всегда встречаются парами.
Отношение R(A,B,C) с многозначной зависимостью А -> ->
В содержит избыточную информацию, хотя и несколько другого рода, чем отношение в 1НФ.
Специальный класс реляционных баз данных, для которых характерна однозначная декомпозиция на основе многозначных зависимостей, называется ациклическими базами данных.
Для определения понятия ациклической схемы БД введем граф соединений на множестве отношений {Sl,S2,...,Sk). Вершинами графа соединений являются имена существующих отношений SI, S2,...,Sk. Дуга графа <Si,Sj> существует, если в структуре отношений Si и Sj имеются общие атрибуты. Обозначим их для определенности через A(i,j) и назовем весом дуги. Путь на графе соединений называется А-путем, если атрибут А содержится в структуре каждого отношения, лежащего на пути. В графе соединений требуется, чтобы для каждой пары отношений Si, Sj с общим атрибутом A(ij) существовал A(ij)- путь между Si и Sj.
Если граф можно превратить в дерево с помощью исключения некоторых дуг при сохранении названного требования, то база данных с отношениями {Sl,S2,...,Sk} является ациклической.
Например, база данных, представленная на рис. 7 является циклической.
 |
Существует простой алгоритм проверки базы данных на ацикличность. Он состоит из двух шагов:
1 шаг. Если некоторый атрибут встречается только в одном отношении, вычеркнуть данный атрибут из этого отношения.
2 шаг. Если все атрибуты некоторого отношения находятся среди атрибутов другого отношения, то первое отношение вычеркивается из списка.
Шаги применяются в любой последовательности. Если в результате будут вычеркнуты все отношения, то БД является ациклической. В противном случае – база данных циклическая.
Восстановление свойств ацикличности БД может быть произведено двумя способами.
1. Добавление в БД нового отношения с атрибутами, равными объединению весов дуг, образующих цикл. В этом случае придется допустить существование неопределенных значений в новом отношении.
2. Добавление новых атрибутов, переименование и разделение атрибутов. Такое решение не требует дополнительных соглашений при интерпретации запросов и не создает дополнительные неопределенные значения.
Например, атрибут Кафедра может быть разделен на два атрибута – Кафедра преподавателя и Выпускающая кафедра.
Критерии, которым соответствует база данных в ЗНФ, и ациклическая БД, безусловно, не совпадают. В первую очередь ациклическая БД не гарантирует минимальную избыточность представления информации. Гарантии единственного пути доступа в ациклической БД, вероятно, следует признать более существенными для пользователей-непрофессионалов. Надо также учитывать элементарность метода проверки ацикличности БД в сравнении с необходимостью формального анализа функциональных зависимостей, требуемых при создании БД в ЗНФ.
§ 2.2. Сетевая и иерархическая модели данных
§ 2.2.1. Основные понятия сетевой модели данных
Информационными конструкциями в сетевой модели данных являются отношения и веерные отношения. Понятие "отношения" уже рассматривалось применительно к реляционной модели данных и будет использоваться здесь без изменений, хотя в некоторых сетевых СУБД допускаются отношения с многоуровневой (три и более) структурой.
Сетевая БД представляется как множество отношений и веерных отношений. Отношения разделяются на основные и зависимые.
Веерным отношением W(R,S) называется пара отношений, состоящая из одного основного R, одного зависимого отношения S и связи между ними при условии, что каждое значение зависимого отношения связано с единственным значением основного отношения.
Названное условие является ограничением, характерным для сетевой модели данных в целом. Способ реализации этого ограничения в памяти ЭВМ неодинаков у различных сетевых СУБД.
Допустимые в сетевой модели данных операции представляют собой различные варианты выборки.
Сетевые базы данных в зависимости от ограничений на вхождение отношений в веерные отношения разделяются на многоуровневые сети и двухуровневые сети.
Ограничение двухуровневых сетей состоит в том, что каждое отношение может существовать в одной из перечисленных ниже ролей:
• вне каких-либо веерных отношении,
• в качестве основного отношения в любом количестве веерных отношений,
• в качестве зависимого отношения в любом количестве веерных отношений.
Запрещается существование отношения в качестве основного в одном контексте и одновременно в качестве зависимого в другом контексте.
Многоуровневые сети не предусматривают никаких ограничений на взаимосвязь веерных отношений, в некоторых сетевых СУБД разрешены даже циклические структуры сети.
Среди существующих в настоящее время сетевых СУБД наиболее распространены системы, поддерживающие двухуровневую сеть. Операция связывания отношений в реляционных СУБД также приводит к двухуровневым системам отношений. Двухуровневые сети обладают свойством ацикличности, о котором будет сказано ниже, и по этой причине очень часто применяются разработчиками ЭИС и прикладными программистами.
Для двухуровневых сетевых СУБД вводятся еще два ограничения (с теоретической точки зрения необязательные):
• первичный ключ основного отношения может быть только одноатрибутным,
• веерное отношение существует, если первичный ключ основного отношения является частью первичного ключа зависимого отношения.
§ 2.2.2. Организация веерного отношения в памяти ЭВМ
В структуру основного и зависимого отношений вводится дополнительный атрибут, называемый адресом связи. Значения адресов связи совместно обеспечивают в веерном отношении соответствие каждого значения зависимого отношения S с единственным значением основного отношения R.
Значение отношения при хранении в памяти ЭВМ часто называется записью. Адресом связи называется атрибут в составе записи, в котором хранится начальный адрес или номер следующей обрабатываемой записи.
Связь значений зависимого отношения с единственным значением основного отношения в простейшем случае обеспечивается следующим образом. Адрес связи некоторой записи основного отношения указывает на одну из записей зависимого отношения (значением адреса связи основного отношения является начальный адрес этой записи зависимого отношения), адрес связи указанной записи зависимого отношения - на следующую запись зависимого отношения, связанную с той же записью основного отношения и т.д. Последняя запись зависимого отношения в этой цепочке адресует названную выше запись основного отношения.
Получается кольцевая структура адресов связи, называемая веером, где роль "ручки" веера играет запись основного отношения. На графических иллюстрациях адрес связи изображается стрелкой, направленной от адреса связи данной записи к той записи, чей начальный адрес (номер) служит значением этого адреса связи. На рис. 8 показаны структуры и значения веерных отношений двух простых сетевых двухуровневых БД. Атрибуты первичного ключа во всех случаях помечены #.
|
Группа(код#, Число студентов) |
Основное отношение |
 |
|
|
Студент (Номер_зач#, Фамилия) |
Зависимое отношение |
|
1311А |
1311Б |
||||||||
    |
 |
||||||||
  |
|||||||||
   |
|||||||||
|
1301 |
1302 |
1303 |
1335 |
1336 |
Рис. 8. Структуры и значения веерных отношений
Схема сетевой БД содержит следующие компоненты:
S(net) = <А,R,WW,Dom,Rе1,Net,V(s)>,
где WW - множество веерных отношений,
Net - вхождение отношений в веерные отношения.
Остальные элементы схемы аналогичны тем, которые введены выше для реляционных баз данных.
Из аналогии определений веерного отношения и функциональной зависимости следует утверждение: если существует веерное отношение, то ключ зависимого отношения функционально определяет ключ основного отношения, и наоборот, ключ одного отношения функционально определяет ключ второго отношения, то первое отношение может быть зависимым, а второе - основным в некотором веерном отношении
Для доказательства достаточно заметить, что в формулировке: каждое значение зависимого отношения связано с единственным значением основного отношения - точным представителем значения отношения является значение его первичного ключа, и отсюда следует приведенная выше формулировка о функциональных зависимостях между ключами.
Указанный факт обычно используется для того, чтобы при наличии функциональной зависимости между первичными ключами двух отношений доказать корректность связывания этих отношений в веерное отношение.
В схеме сетевой БД отношения и веерные отношения трактуются как файлы и связи, что позволяет рассматривать сетевую структуру как множество файлов
F = {F1(Х1), F2(Х2),..,Fi(Хi),...,Fn(Хn)},
где Xi - атрибуты ключа в файле Fi.
Дополнительно вводится граф сетевой структуры В с вершинами {Х1, Х2,...,Х1,...,Хn}. Дуга <Хi,Хj> в графе В существует, если Xi является частью Xj и Fj[Хi] является подмножеством Fi. Последнее условие имеет тот же смысл, что и синтаксическое включение отношений в реляционной модели данных. Здесь предполагается, что ключ основного файла содержится в зависимом файле. Граф В аналогичен графу соединений реляционной БД.
Введем определение сетевой ациклической базы данных DBA. База данных DBA называется ациклической, если между любыми двумя вершинами на графе В существует не более одного пути. Двухуровневые сети всегда ациклические.
Для множества файлов F ациклической базы данных DВА вполне применима операция
m(DВА) == F1 & F2 & ... & Fi1 & ...& Fn,
называемая максимальным пересечением. Ее аналогом может служить последовательность соединений в реляционной БД.
Рассмотрим алгоритм формирования структуры двухуровневой сетевой БД на основе известного множества атрибутов и функциональных зависимостей.
Исходное множество функциональных зависимостей и атрибуты первичного ключа получаются так же, как при формировании множества отношений в ЗНФ.
§ 2.2.3. Алгоритм получения двухуровневой структуры сети
1. Для каждой функциональной зависимости вида А>В создается файл Fi(А,В). Каждый блок взаимно-однозначных соответствий также порождает файл с ключом, равным старшему по объему понятия атрибуту.
В нашем примере будут созданы следующие файлы (ключи помечены знаком #):
F1(ПРИ #, Директор, Адрес),
F2(0тдел #, ПРИ, Таб№сотр),
FЗ(Код_проекта #, Датанач, Датакон, Стоимость),
F4(ФИО #, Отдел),
F5(Код_проекта #, Работа #, ФИО #, Прод),
F6(Код_проекта #, Заказ #, ГИП).
2. У всех пар файлов, полученных на шаге 1, проверяется условие для ключей (Кi является частью Кj)). Если оно соблюдается, то из соответствующих файлов создается веерное отношение Wij(Fi,Fj).
В нашем примере получим W35(FЗ,F5), W45(F4,F5), W36(FЗ,F6).
3. Если на шаге 2 будут получены два веерных отношения Wij, Wjk то все атрибуты файла Fi передаются в файл Fj, и Fi вместе с Wij уничтожаются. В нашем примере таких веерных отношений нет.
4. Атрибуты, не вошедшие в состав веерных отношений на шаге 2, добавляются в те файлы Fn (и содержащие Fn веерные отношения), где они будут неключевыми. При наличии нескольких подходящих файлов предпочтение отдается основным файлам. Если требуемые Fn отсутствуют, то создается новый файл из атрибутов первичного ключа, и повторяются шаги 2,3,4.
В нашем примере F4 расширяется атрибутами ПРИ, Директор, Адрес, Таб№сотр.
На рис.2.3 показана структура соответствующей двухуровневой БД.
Структуры основных отношений показаны в верхней части рисунка, а структуры зависимых отношений - внизу.
Перед рассмотрением операций в сетевой базе данных следует отметить, что существуют 2 различных подхода к обработке данных средствами СУБД.
Для сетевой БД характерен принципом доступа к данным, называемый навигационным.
Центральным для навигационного принципа доступа является понятие "текущая запись" в отношениях базы данных.
Текущей записью в отношениях после выполнения некоторой операции является значение отношения, на котором операция завершилась. Следующая операция начинается с этой текущей записи, а в результате выполнения операции положение текущей записи изменяется (завершение операции может изменить положение текущей записи и в других отношениях).
Для сетевой базы данных характерна такая операция, как выборка.
|
ФИО Отдел# ПРИ Директор Адрес Таб№сотр |
Код_проекта# Датанач Датакон Приор |
|
   |
||
|
Код_проекта# Работа# ФИО# Прод |
Код проекта# Заказ# ГИП |
§ 2.2.4. Иерархическая модель данных
Иерархическая модель данных имеет много общих черт с сетевой моделью данных, хронологически она появилась даже раньше, чем сетевая. Допустимыми информационными конструкциями в иерархической модели данных являются отношение, веерное отношение и иерархическая база данных. В отличие от ранее рассмотренных моделей данных, где предполагалось, что информационным отображением одной предметной области является одна база данных, в иерархической модели данных допускается отображение одной предметной области в несколько иерархических баз данных.
Понятия отношения и веерного отношения в иерархической модели данных не изменяются.
Иерархической базой данных называется множество отношений и веерных отношений, для которых соблюдаются два ограничения.
1. Существует единственное отношение, называемое корневым, которое не является зависимым ни в одном веерном отношении.
2. Все остальные отношения (за исключением корневого) являются зависимыми отношениями только в одном веерном отношении.
Схема иерархической БД по составу компонентов идентична сетевой базе данных. Названные выше ограничения поддерживаются иерархическими СУБД.
На рис. 10 изображена структура иерархической базы данных, удовлетворяющая всем ограничениям, указанным в определении.
Ограничение, которое поддерживается в иерархической модели данных, состоит в невозможности нарушения требований, фигурирующих в определении иерархической базы данных. Это ограничение обеспечивается специальной укладкой значений отношений в памяти ЭВМ. Ниже мы рассмотрим одну из простейших реализаций укладки иерархической БД.
 |
Рис. 10. Иерархическая база данных
На рис. 11 приводится линейная организация значений из иерархической базы данных, структура которой показана на рис. 10.
Необходимо отметить, что существуют различные возможности прохождения иерархически организованных значений в линейной последовательности. Принцип, применяемый для иерархических баз данных, называется концевым прохождением.
Правила концевого прохождения:
1. Начиная с первого значения корневого отношения, перечисляются первые значения соответствующих отношений на каждом уровне вплоть до последнего.
2. Перечисляются все значения в том веерном отношении, на котором остановился шаг 1.
3. Перечисляются значения всех вееров этого веерного отношения в иерархической базе данных:
4. От достигнутого уровня происходит подъем на предыдущий уровень, и если возможно применить шаг 1, то процесс повторяется.
Записью иерархической базы данных называется множество значений, содержащих одно значение корневого отношения и все вееры, доступные от него в соответствии со структурой иерархической базы данных.
Для веерных отношений в составе иерархической базы данных справедлива уже известная закономерность: если существует веерное отношение, то ключ зависимого отношения функционально определяет ключ основного отношения, и наоборот, если ключ одного отношения функционально определяет ключ второго отношения, то первое отношение может быть зависимым, а второе - основным в некотором веерном отношении.
Запись 1
|
Б=01 |
Лаб=01 |
Лаб=02 |
Пал=01 |
Пац=01 |
… |
Пац=04 |
Пал=02 |
Пац=01 |
|
|
… |
Пац=06 |
… |
Пал=20 |
Пац=01 |
… |
Пац=04 |
Вр=01 |
Вр=02 |
|
|
… |
Вр=40 |
||||||||
 |
|||||||||
|
Б=02 |
Лаб=01 |
Лаб=02 |
Пал=01 |
Пац=01 |
… |
Пац=05 |
Пал=02 |
Пац=01 |
|
|
… |
Пац=04 |
… |
Пал=30 |
Пац=01 |
… |
Пац=04 |
Вр=01 |
Вр=02 |
|
|
… |
Вр=60 |
||||||||
Рис. 11. Линейное представление значений
Кроме того, ограничение на существование единственного корневого отношения в иерархической базе данных трансформируется в требование: первичный ключ каждого некорневого отношения должен функционально определять первичный ключ корневого отношения.
§ 2.3. Сравнение моделей данных
На окончательный выбор моделей данных влияют многие дополнительные факторы, например, наличие хорошо зарекомендовавших себя СУБД, квалификация прикладных программистов, размер баз данных и прочее.
Например одна и та же задача может быть реализована различными моделями данных, что представлено на рис. 12.
Рассмотрим преимущества и недостатки известных моделей данных.
Реляционная модель
Преимущества:
Простота. В реляционной модели всего одна информационная конструкция (двухуровневое отношение), которая формализует табличное представление данных, привычное для пользователей-экономистов.
Теоретическое обоснование. Наличие теоретически обоснованных методов нормализации отношений и проверки БД на ацикличность позволяет получать базы данных с заданными характеристиками.
Независимость данных. Когда необходимо изменить структуру реляционной БД, это, как правило, приводит к минимальным изменениям в прикладных программах.
Недостатки:
Низкая скорость при выполнении операции соединения.
Большой расход памяти для представления реляционной БД. Хотя проектирование в ЗНФ рассчитано на минимальную избыточность, другие модели данных обеспечивают меньший расход памяти для представления тех же фактов. Например, длина адреса связи обычно намного меньше, чем длина значения атрибута.
Иерархическая модель
Преимущества:
Простота. Хотя модель использует три информационные конструкции, иерархический принцип соподчиненности понятий является естественным для многих экономических задач (например, организация статистической отчетности).
Минимальный расход памяти. Для задач, допускающих реализацию с помощью любой из трех моделей данных, иерархическая модель позволяет получить представление с минимально требуемой памятью.
Недостатки:
Неуниверсальность. Многие важные варианты взаимосвязи данных невозможно реализовать средствами иерархической модели, или реализация связана с повышением избыточности в базе данных.
Допустимость только навигационного принципа доступа к данным.
Доступ к данным производится только через корневое отношение.
Сетевая модель
Преимущества:
Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями.
Возможность доступа к данным через значения нескольких отношений (например, через любые основные отношения).
Недостатки:
Сложность, т.е. обилие понятий, вариантов их взаимосвязей и особенностей реализации.
Допустимость только навигационного принципа доступа к данным.
Результаты, полученные для ациклических баз данных, позволяют говорить о равноценных возможностях представления информации в ациклических реляционных БД, двухуровневых сетевых БД и иерархической БД без логических связей.
При анализе моделей данных не затрагивалась проблема упорядоченности значений в отношениях баз данных. Для реляционной модели данных эта упорядоченность с теоретической точки зрения необязательна, а в двух других моделях она широко используется для повышения эффективности реализации запросов.
Проект
|
№ проекта |
 |
Местоположение |
|
№ поставщика |
Наименование |
Местонахождение |

Деталь
|
№ детали |
Наименование |
Вес |
Количество |
Проект (№ проекта, название, местоположение);
Поставщик (№ поставщика, наименование, местонахождение);
Деталь (№ детали, наименование, вес);
Поставка (№ проекта, № поставщика, № детали, количество).
Реляционная модель
Проект Поставщик
|
№ пректа |
Название |
Местопо-ложение |
№ поставщика |
Наимено-вание |
Местонахож-дение |


Поставка
 |
|
№ детали |
Наименование |
Вес |
Рис. 12. Различные модели данных для реализации одной задачи
В последнее время реляционные СУБД заняли преимущественное положение как средство разработки ЭИС. Недостатки реляционной модели компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ. Вследствие процессов децентрализации управления в экономике многие базы данных ЭИС имеют простую структуру, которая легко трансформируется в понятие системы таблиц (отношений).
§ 2.4. Модель инвертированных файлов и
информационно-поисковые системы
Основными информационными конструкциями в модели инвертированных файлов являются основной файл, который соответствует ранее введенному понятию “отношения”, “информационный файл” и “список связи”.
Множество основных файлов базы данных обозначим через {F1, F2,...,Fn}. Все записи файлов F1...Fn получают в пределах базы данных единую нумерацию.
В основном файле Fi выделяется один или несколько атрибутов, по значениям которых затем будут формироваться инвертированные файлы и списки связи. С точки зрения ранее рассмотренной реляционной модели данных выделяемый атрибут может быть как первичным, так и вторичным ключом в основном файле Fi.
Естественно, что выделенный атрибут (обозначим его А) может принимать в Fi несколько различных значений {а(1),а(2),…,а(k)}. Поставим в соответствие каждому значению а(j) множество номеров записей файла Fi, в которых это значение связано с именем атрибута А.
{а(1), n(t), n(р),...}
{а(2), n(g), n(h),...}
..............................
{а(j), n(х), n(у),..}
..............................
Через n с соответствующим индексом обозначены номера записей из Fi.
Определенная таким образом последовательность значений атрибута А и номеров записей основного файла Fi является инвертированным файлом, который далее будем обозначать через А(Fi).
Чтобы определить понятие списка связи, необходимо отметить, что единая нумерация всех записей базы данных приводит к тому, что номер записи становится первичным ключом во всех основных файлах базы данных независимо от того, какие атрибуты образуют ключ в каждом из этих файлов.
Рассмотрим два файла Fi и Fm, в структуре которых имеется общий атрибут А. В этой ситуации существуют два списка связи (Fi, Fm) и (Fm, Fi). В списке (Fi, Fm) для каждого номера записи из файла Fi указываются номера записей из файла Fm, имеющие то же самое значение атрибута А. Аналогично определяется содержимое списка связи (Fm, Fi).
Аналогия с двухуровневой сетью заключается в следующем. Связь инвертированного файла А(Fi) и файла Fi соответствует типу "основной-зависимый". Отличия сводятся к тому, что атрибут А не имеет никакого отношения к первичному ключу Fi (в двухуровневой сети он должен быть частью первичного ключа), и, кроме того, вместе с атрибутом А в инвертированном файле запрещено хранить значения других атрибутов.
Например, в базе данных содержатся основные файлы Магазин и Объем продаж.
|
Магазин |
Объем продаж |
||||
|
Название магазина |
Продукция |
Название магазина |
Дата |
Объем продаж |
|
|
01 Весна |
Видеокассеты |
05 Вега |
01.07 |
20 |
|
|
02 Вега |
Аудиокассеты |
06 Весна |
01.07 |
15 |
|
|
03 Альтаир |
Видеокассеты |
07 Плаза |
01.07 |
25 |
|
|
04 Плаза |
Аудиокассеты |
08 Альтаир |
01.07 |
18 |
|
|
09 Вега |
02.07 |
15 |
|||
|
10 Весна |
02.07 |
20 |
|||
|
11 Вега |
03.07 |
25 |
Видеокассеты – 01, 03
Аудиокассеты – 02, 04
Список связи (Магазин, Объем продаж)
01 – 05, 09, 11
02 – 06, 10
03 – 07
04 - 08
Преимущества модели инвертированных файлов особенно проявляются при реализации выборки с большим количеством условий. Каждое условие выборки соответствует множеству номеров записей, и комбинация условий выборки означает манипулирование ранее полученными из инвертированных файлов множествами номеров записей.
В информационно-поисковых системах ключевые атрибуты соответствуют ключевым словам, определяющим тематику документа. Количество ключевых слов для документа может быть любым.
Связь основного и инвертированного файла в этом случае выглядит иначе и показана на рис. 13.
Пусть дан запрос: найти все документы, содержащие ключевые слова B и D. Система обратится к инвертированному файлу и найдет группы ключей B и D. Совпадающие значения номеров укажут в нашем примере на искомую запись с номером 110.
Ключевые слова А, В, С, D, Е
|
Номер записи |
Основной файл |
Инвертированный файл |
|
|
50 |
A B |
A 50 |
|
|
105 |
B C |
||
|
110 |
B D E |
B 50 |
|
|
120 |
C D |
105 |
|
|
110 |
|||
|
C 105 |
|||
|
120 |
|||
|
D 110 120 |
|||
|
|
|||
|
E 110 |
|||
Логические связки в запросах могут быть любыми, и с математической точки зрения требуемые поисковые операции есть операции пересечения, объединения, вычитания над множествами номеров записей, которые хранятся в инвертированных массивах для атрибутов, названных в запросе.
Следует отметить, что поиск по инвертированному файлу обнаруживает только номера записей и плохо приспособлен для указания всех ключей, связанных с найденной записью. Между тем эта информация часто запрашивается. В одном из наших примеров запись с адресом 110 была найдена по значениям ключей B и D очень быстро, но определить, есть ли в этой записи третий ключ Е, используя только инвертированный файл, очень трудно.
Модель инвертированных файлов служит основой для ряда современных информационно-поисковых систем. Одна база данных создается обычно для одного класса документов, которые объединены общей тематикой, например, справочная информация о предприятиях и организациях, сведения о производимой продукции, информация о происходящих выставках.
С учетом реляционного подхода одна база данных в таком случае соответствует одному отношению.
Значением атрибута может быть текст произвольных размеров, причем разбиение этого текста на строки может варьироваться и не должно влиять на реализацию поисковых запросов.
Документ может сопровождаться графической иллюстрацией, и в таком случае ее предоставление определяется средствами компьютерной графики. Изображение не является значением какого-то атрибута в общепринятом смысле слова, поскольку как значение не может участвовать в операциях выборки.
Из всего многообразия реализаций информационно-поисковых языков модели инвертированных файлов соответствуют дескрипторные языки.
Дескриптором, или ключевым словом, называется слово или словосочетание, используемое для краткого обозначения темы документа, хранящегося в базе данных информационно-поисковой системы. Конкретный документ может сопровождаться несколькими дескрипторами в зависимости от количества характеризующих его терминов.
Получение списка дескрипторов для каждого конкретного документа является достаточно сложной и трудоемкой задачей, которую обычно решают специалисты в той области знаний, которой посвящена информационно-поисковая система.
Один из более простых подходов к определению списка дескрипторов для всех документов в базе данных заключается в том, что из всех атрибутов документа выбирается несколько наиболее информативных, и все слова, составляющие значения таких атрибутов, переносятся в список дескрипторов. Разумеется, при таком методе получения дескрипторов должна быть исключена ситуация попадания в дескрипторы явно неинформативных частей речи (предлогов, местоимений и некоторых других).
Второй проблемой является необходимость отбрасывать в словах-дескрипторах окончания слов, чтобы употребление одного и того же термина в разных словосочетаниях не приводило к появлению множества дескрипторов, различных по написанию, но обозначающих одно и то же понятие.
В каждой информационно-поисковой системе должна присутствовать административная подсистема и поисковая подсистема.
Административная подсистема предназначена для организации новых баз данных, определения структуры вводимых в них записей, ввода подготовленных документов в базы данных в соответствии с определенными структурами, а также для создания главного инвертированного файла - основного средства ускорения поиска требуемой информации в ИПС с помощью ключевых слов.
Модель инвертированных файлов можно рассматривать как частный случай сетевой двухуровневой модели данных. Произведенные упрощения двухуровневой сети позволили создать еще более понятную прикладным программистам и пользователям модель данных.
Вопросы и задания
1. Назовите компоненты моделей данных.
2. Приведите схемы реляционной, сетевой и иерархической моделей данных.
3. Назовите операции, выполняемые над отношениями в реляционной модели данных.
4. Что такое натуральное соединение?
5. Как выполняется деление отношений и что такое «образ»?
6. Какова цель нормализации отношений?
7. Приведите примеры отношений в 1НФ, 2НФ, 3НФ.
8. По какому принципу организовано веерное отношение?
9. Назовите правила концевого прохождения?
10. Определите отношение в третьей нормальной форме для следующего списка атрибутов и функциональных зависимостей.
а)
Атрибуты Функциональные зависимости
ФИО вкладчика № сберкнижки > ФИО
№ сберкнижки № сберкнижки, Дата > Расход
Дата № сберкнижки, Дата > Расход
Приход № сберкнижки, Дата > Остаток
Расход № сберкнижки, Дата > Приход, Расход, Остаток
Остаток № сберкнижки, Дата > Приход
б)
Атрибуты Функциональные зависимости
Таб. номер Участок > Цех
ФИО Таб. номер > Цех
Цех Таб. номер > Участок
Дата Таб. номер, Дата > Сумма
Участок Таб. номер > ФИО
Сумма Таб. номер, ФИО > Участок
ГЛАВА 3. МЕТОДЫ ОРГАНИЗАЦИИ ДАННЫХ
§3.1. Анализ алгоритмов и структур данных
Данные в памяти ЭВМ обычно хранятся раздельно в виде составных единиц информации. Отдельное значение СЕИ, находящееся в памяти ЭВМ, называется записью. Множество записей образует массив, или файл.
Термин массив обычно используется при рассмотрении данных в оперативной памяти ЭВМ, термин файл применяется для данных, хранимых на внешних запоминающих устройствах.
Организацией значений данных – это относительно устойчивый порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между записями.
Организация значений данных (далее называемая просто организацией данных) может быть линейной и нелинейной (Рис. 14).


Линейные Нелинейные
 |
 |
 |
|||

Бинарное дерево
Рис. 14. Методы организации данных
При линейной организации данных каждая запись, кроме первой и последней, связана с одной предыдущей и одной последующей записями. У записей, соответствующих нелинейной организации данных, количество предыдущих и последующих записей может быть произвольным.
Линейные методы организации данных различаются только способами указания предыдущей и последующей записи по отношению к данной записи. Но это приводит к тому, что алгоритмы, эффективные для одних методов организации данных, становятся неприемлемыми для других методов.
Среди линейных методов выделяются последовательная и цепная организации данных. При последовательной организации данных записи располагаются в памяти строго одна за другой, без промежутков, в той последовательности, в которой они обрабатываются. Последовательная организация данных обычно и соответствует понятию массив (файл).
Записи в массиве, с точки зрения способа указания их длины делятся на записи фиксированной, переменной и неопределенной длины. Записи фиксированной (постоянной) длины имеют одинаковую, заранее известную длину.
Адреса промежуточных записей фиксированной длины в массиве задаются формулой:
А(i) = А(l)+(i-1)*L,
где А(1) - начальный адрес первой записи;
А(i) - начальный адрес i-й записи;
L - длина одной записи.
Если длины записей неодинаковы, то длина указывается в самой записи. Такие записи называют записями переменной длины. Вместо явного указания длины записи можно отмечать окончание записи специальным символом-разделителем, который не должен встречаться среди информационных символов значения записи. Записи, заканчивающиеся разделителем, называются записями неопределенной длины. Записи переменной и неопределенной длины занимают меньший объем памяти, но их обработка ведется с меньшей скоростью, поскольку затруднено обнаружение следующей записи.
В структуре записей последовательного массива обычно выделяется один или несколько ключевых атрибутов, по значениям которых происходит доступ к остальным значениям атрибутов той или иной записи. Ключевые атрибуты в записях обозначаются через р(i), где i - номер записи, общее число записей в массиве обозначается через М.
Записи массива могут быть упорядоченными или неупорядоченными по значениям ключевого атрибута (ключа), имя которого одинаково во всех записях. Ключевой атрибут обычно является атрибутом-признаком. Часто требуется поддерживать упорядоченность записей по нескольким именам ключевых признаков. В этом случае среди признаков устанавливается старшинство. Условие упорядоченности записей в массиве (и вообще для линейной организации данных) выглядит следующим образом:
р (i) <=р (i+ 1)- упорядоченность по возрастанию;
р(i) >= р(i+1) - упорядоченность по убыванию.
Наиболее важными и часто применяемыми алгоритмами обработки данных являются формирование данных, их поиск и корректировка, а также последовательная обработка. Эти алгоритмы могут быть реализованы с использованием достаточно большого количества методов организации данных.
§ 3.2. Сравнение методов организации данных
Для сравнения методов организации данных обычно анализируются следующие величины:
• время формирования данных, т.
е. время создания в памяти ЭВМ так или иначе упорядоченного представления данных (упорядочение способно ускорить выполнение алгоритмов поиска данных);
• время поиска данных. Как известно, условия поиска (выборки) на практике могут быть достаточно разнообразные. Анализируется обычно простейший и наиболее распространенный случай (поиск по совпадению) – найти записи, у которых значение ключевого атрибута равно заранее известной величине q;
• время корректировки данных. Из всех возможных вариантов корректировки учитывается включение или исключение одной записи;
• объем дополнительной памяти, расходуемой под служебную информацию (например, адреса связи).
На время выполнения алгоритмов влияет и ряд других факторов, например, быстродействие конкретной ЭВМ, применяемый язык программирования, стиль программирования конкретного программиста. Чтобы можно было не принимать во внимание подобные факторы, целесообразно анализировать не время, а количество выполняемых элементарных операций, в частности операций сравнения значений ключевых атрибутов и искомых величин. Время выполнения алгоритма обычно прямо пропорционально числу требуемых сравнений, и подобная замена критерия эффективности алгоритма вполне законна.
При анализе алгоритмов необходим еще ряд допущений, обеспечивающих использование равномерного распределения вероятностей для всех случайных величин, описывающих работу алгоритма, в том числе:
• распределение значений ключевых атрибутов в массиве из М записей - равномерное;
• значение q при поиске по совпадению выбрано случайно: это означает, что поиск с одинаковой вероятностью 1/М может закончиться на любой записи массива;
• положение включаемой (исключаемой) записи при корректировке определяется теми же вероятностями, что и при поиске.
Массив, обладающий наибольшей неопределенностью своего состояния, будем называть случайным массивом. Все его М! состояний равновозможны. Через М! обозначено произведение 1*2*...*М.
Таким образом, минимальное число сравнений, необходимое для упорядочения массива из М записей, определяется как
С = log М!,
что соответствует минимально возможному числу вопросов о состоянии массива с возможными ответами типа: да – нет (логарифм по основанию 2).
Сравнение методов организации данных Табл. 1.
|
Методы организации данных |
Лучший метод |
|||
|
Критерии оценки |
последовательный |
цепной |
бинарное дерево |
|
|
Время формирования |
~ М log М |
~ М log М |
~ М log М |
цепной, бинарное дерево |
|
Время поиска |
~ log М |
~ М |
~ log М |
последовательный, бинарное дерево |
|
Время корректировки |
~ М |
~ М |
~ log М |
бинарное дерево |
|
Объем дополнительной памяти |
0 |
~ М |
~ М |
последовательный |
Поиск в последовательном массиве
Поиском называется процедура выделения из некоторого множества записей определенного подмножества, записи которого удовлетворяют некоторому заранее поставленному условию, называемому запросом на поиск. Простейшее условие поиска – это поиск по совпадению, т. е. равенство значения ключевого атрибута i-й записи р(i) и некоторого заранее заданного значения q.
Базовым методом доступа к массиву является ступенчатый поиск. Этот метод предполагает упорядоченность обрабатываемых записей по возрастанию или по убыванию. Для определенности будем считать, что массив отсортирован по возрастанию значений ключевого атрибута р(i).
Рассмотрим простейший вариант ступенчатого поиска – одноступенчатый или последовательный поиск. Искомое значение q сравнивается с ключом первой записи, если значения не совпадают, с ключом второй записи и т.
д. до тех пор, пока q не станет больше ключа очередной записи.
Для двухступенчатого поиска в массиве, состоящем из М записей выбирается константа d1, называемая шагом поиска. Если необходимо отыскать запись со значением ключевого атрибута, равным q, производятся следующие действия.
Значение q последовательно сравнивается с рядом величин р(1), р(1+d1), р(1+2*d1), ..., р(1+k*d1) до тех пор, пока будет впервые достигнуто неравенство р(1+m*d1) =>q. Здесь заканчивается первая ступень поиска. На второй ступени q последовательно сравнивается со всеми ключами, которые имеют номер 1+m*d1 и больше, до тех пор, пока в процессе сравнений будет достигнут ключ, больший, чем q. Извлеченные при этом записи с ключом q образуют результат поиска.
Эффективность поиска измеряется количеством произведенных сравнений.
Важным вариантом ступенчатого поиска является бинарный поиск. Для бинарного поиска вводятся левая граница интервала поиска А и правая граница В. Первоначально интервал охватывает весь массив, т. е. А=0, В=М+1. Вычисляется середина интервала i по формуле i=(А+В)/2 с округлением в меньшую сторону. Ключ i-й записи р(i) сравнивается с искомым значением q. Если р(i) = q, то поиск заканчивается. В случае р(i)>q записи с номерами i+1, i+2,..., М заведомо не содержат ключа, и надо сократить интервал поиска, приняв В=i. Аналогично при р(i) < q надо взять А=i. Далее середина интервала вычисляется заново, и все действия повторяются. Если будет достигнут нулевой интервал, то требуемой записи в массиве нет.
Корректировка последовательного массива
Корректировка массива может касаться одной его записи или группы записей. Отдельная запись может включаться в массив и исключаться из него. Кроме того, в записи могут быть изменены значения отдельных атрибутов (как правило, неключевых). В любом случае перед непосредственно корректировкой выполняется поиск местонахождения корректируемой записи.
Включение новой записи (например, со значением ключевого атрибута q в последовательный упорядоченный массив не должно нарушать его упорядоченность.
Поэтому сначала необходимо найти положение новой записи относительно имеющихся в массиве записей, т. е. выполнить поиск ключа новой записи q. Если значения q в массиве нет, то поиск остановится там, где должна находиться запись с ключом q при сохранении общей упорядоченности массива. Новая запись не может сразу занять место, где остановился поиск, необходимо выполнить пересылку записей, чтобы освободить его. Пересылка начинается с последней записи (она после пересылки занимает следующую позицию по направлению к концу массива), затем предпоследняя запись пересылается на место последней и т. д. В результате освобождается место для новой записи.
Итак, время включения записи складывается из времени поиска и времени пересылки записей. В среднем пересылка затрагивает примерно половину записей массива. Время пересылки одной записи пропорционально ее длине.
При исключении записи из массива также необходимо сначала найти в массиве ключ удаляемой записи, а затем выполнить пересылки записей в направлении к началу массива для уничтожения исключаемой записи в памяти. Очевидно, что время исключения записи описывается той же формулой, что и время включения записи.
Можно прийти к выводу, что включение-исключение записей поодиночке является очень длительной процедурой. Поэтому в ряде случаев удобно накапливать корректирующие записи в специальном массиве изменений, а не вносить их по мере появления.
Массив записей, подвергающихся изменениям, называется основным. Изменения, которые необходимо внести в основной массив, накапливаются в специальном упорядоченном массиве изменений, рассчитанном на 1<=m<=М записей. Обычно m составляет несколько процентов от М. При необходимости обработки основного массива он объединяется с массивом изменений.
При объединении основного массива с массивом изменений выполняются следующие операции (алгоритм слияния):
• ключ очередной записи основного массива сравнивается с ключом очередной записи массива изменений, и запись с меньшим значением ключа добавляется в новый массив (результат слияния);
• когда все записи одного из массивов будут перезаписаны полностью, оставшиеся записи другого массива добавляются в результирующий массив, и алгоритм заканчивается.
§ 3.3. Цепная (списковая) организация данных
Решение целого ряда задач обработки данных требует применения таких методов организации данных, которые позволили бы связать физически разнесенные в памяти данные в логическую последовательность, определяющую порядок их обработки. Простейшим методом, применяемым для этих целей, является списковая (цепная) организация данных.
Списком называется множество записей, занимающих произвольные участки памяти, последовательность обработки которых задается с помощью адресов связи. Адресом связи некоторой записи называется атрибут, в котором хранится начальный адрес или номер записи, обрабатываемой после этой записи. Обычная последовательность обработки записей в списке определяется возрастанием значений ключа в записях.
В списке выделяется собственная информация (записи с содержательными сведениями) и ассоциативная информация, т. е. все адреса связи.
Возможны два способа организации списка - совместное размещение собственной и ассоциативной информации, когда запись и ее адрес связи образуют одно целое (рис. 15, а), и раздельное, когда имеется списковая организация адресов связи и последовательное хранение собственной информации (рис. 15, б). При списковой организации данных необходим специальный атрибут, называемый указателем списка, который содержит начальный адрес или номер первой в порядке обработки записи списка.
Адреса связи
  |
Ø |
|||||||
|
Указатель |
1 |
2 |
3 |
4 |
а) Записи
Ассоциативная информация
     |
Ø |
|||||||||||
|
Указатель |
||||||||||||
|
списка |
1 |
2 |
3 |
4 |
б) Записи
Рис. 15. Варианты списковой организации данных:
а) - совместное хранение записей и адресов связи;
б) - раздельное хранение записей и адресов связи
(Ø – конец списка)
Кроме того, адрес связи последней записи списка должен содержать специальное значение, называемое концом списка и отмечающее, что последующих записей у данной записи нет. Обычно конец списка отмечается нулем.
На рисунках адрес связи изображается прямоугольником со стрелкой, стрелка указывает на запись, адрес хранения которой содержится в адресе связи.
При формировании упорядоченного списка записей возможны два варианта:
• вновь поступающие записи вставлять так, чтобы не нарушать упорядоченность по ключу;
• создать сначала неупорядоченный список, а затем отсортировать его.
Учитывая, что для сортировки можно использовать метод слияния, второй вариант следует признать более целесообразным.
В итоге время формирования упорядоченного списка пропорционально Т~М*1оgМ.
Поиск в упорядоченном списке основан на использовании тех же методов, что и в последовательном массиве, но так как адреса связи создают возможность быстрого доступа только к следующей записи, эффективность этих методов иная.
Последовательный поиск применяется для поиска данных в однонаправленном списке. Ключевой атрибут сравнивается с искомым значением, затем происходит переход по адресу связи к следующей записи и т. д. Время поиска пропорционально количеству записей Т~М.
Бинарный поиск для списковой организации является неэффективным, так как число переходов от записи к записи при доступе к середине интервала представляется величиной практически равной количеству записей.
При применении двунаправленных и кольцевых списков время доступа к записям уменьшается. На рис. 16 приведены примеры этих списков.
Адреса связи Указатель
обратного
  |
Ø |
|||||||||
  |
Ø |
|||||||||
   |
направления |
|||||||||
|
направления |
||||||||||
|
1 |
2 |
3 |
4 |
а) Записи
 |
       |
||||||||||||
|
Указатель |
||||||||||||
|
списка |
1 |
2 |
3 |
4 |
Рис. 16. Организация списков: а) двунаправленная; б) кольцевая
Двунаправленный список образован двумя цепочками адресов связи - от первой записи к последней и от последней записи к первой. В кольцевом списке последний адрес связи указывает на первую запись.
§ 3.4. Цепной каталог
Цепной каталог – это сплошной участок памяти (или несколько таких участков), в котором одновременно размещаются список обрабатываемых записей и список свободных позиций памяти. Адрес связи, отмечающий первую обрабатываемую запись, называется указателем списка. Адрес связи, отмечающий первую свободную позицию памяти, называется указателем свободной памяти. Адрес связи последней записи (или последней позиции свободной памяти) в списке называется концом списка и отмечается нулевым значением.
Включение и исключение записей в цепном каталоге предполагает поиск местоположения включаемой (исключаемой) записи и замену значений адресов связи для установления новой последовательности записей основного списка и списка свободной памяти.
Для того, чтобы включить или исключить запись в цепном каталоге необходимо найти местоположение записи и заменить значения адресов связи для установления новой последовательности основного списка и списка свободной памяти.
Оценка времени корректировки складывается из времени реализации поиска и времени на замену значений адресов связи.
В последнем случае число пересылок адресов связи всегда одинаково и не зависит от числа записей в цепном каталоге, поэтому затраты времени на поиск при корректировке являются доминирующими и время корректировки пропорционально количеству записей Т~М.
§ 3.5. Древовидная организация данных
Древовидной организацией данных (деревом) называется множество записей, расположенных по уровням следующим образом:
•на 1-м уровне расположена только одна запись (корень дерева),
• к любой записи i-го уровня ведет адрес связи только от одной записи уровня i-1.
В данном определении понятия "дерево" и "уровень" вводятся одновременно. Если записи получат номера уровней, соответствующие определению, то они получат и древовидную организацию.
Количество уровней в дереве называется рангом. Записи дерева, которые адресуются от общей записи (i-1)-го уровня, образуют группу. Максимальное число элементов в группе называется порядком дерева. В дереве на рис. 17 порядок равен 3 и ранг составляет 4 (записи дерева обозначены заглавными латинскими буквами).
Деревья обычно формируются двунаправленными, адрес связи от записи уровня i+1 к записи i-го уровня называется обратным.
При размещении дерева в памяти ЭВМ каждая запись может занимать произвольное место.
 |
 |


 |
|||||
 |
 |
||||
 |
 |

|
|
|
|
|
|
|





 |
|||
 |
Рис. 18. Представление древовидной организации данных в памяти ЭВМ
Назовем звеном связи набор адресов связи, принадлежащих одной записи. Если порядок дерева равен р, то звено связи состоит из р+1 адресов (один адрес обратный, определяющий связь с записью непосредственно более высокого уровня). Корень дерева адресуется из специального указателя дерева. Незанятые адреса связи содержат признак конца списка. В качестве примера размещения дерева в памяти ЭВМ на рис. 18 показан один из возможных вариантов представления дерева с рис. 17, обратные адреса связи не показаны.
Рассмотрим бинарные деревья (порядка 2 ). Они интересны тем, что составляющие их записи могут быть упорядочены. Для этого один из атрибутов записи должен быть объявлен ключевым.
Чтобы определить понятие упорядоченности бинарных деревьев, требуется ввести ряд новых понятий. В качестве примера рассмотрим бинарное дерево на рис. 19 (внутри показаны значения ключевого атрибута). Запись А - корень дерева. Записи, у которых заполнены два адреса связи, называются полными, записи с одним заполненным адресом - неполными, записи с двумя незаполненными адресами - концевыми. На рис. 19 записи А, В, Е, C- полные, G - неполная. D, F, T, H, R - концевые.
 |
Адреса связи делятся на левые и правые. Каждая запись имеет левую и правую ветви. Правую (левую) ветвь записи образует поддерево, адресованное из этой записи через правый (левый) адрес связи. В упорядоченном бинарном дереве значение ключевого атрибута каждой записи должно быть больше, чем значение ключа у любой записи на ее левой ветви, и не меньше, чем ключ любой записи на ее правой ветви.
Упорядоченное бинарное дерево формируется из неупорядоченного массива записей по специальному алгоритму.
Вопросы и задания
1. Назовите критерии оценки методов организации данных.
2. Почему время формирования массива у бинарного дерева и цепной организации данных меньше, чем у последовательной для одинакового количества записей?
3. В чем заключается бинарный поиск?
4. Что такое корень дерева, ранг, и порядок?
5. Приведите схемы списковой организации данных при совместном и раздельном хранении записей и адресов связи.
6. По какой формуле определяются адреса промежуточных записей фиксированной длины?
ГЛАВА 4. МОДЕЛИРОВАНИЕ ПРЕДМЕТНЫХ
ОБЛАСТЕЙ В ЭКОНОМИКЕ
§ 4.1. Семантические модели данных
Напомним, что предметной областью называется подмножество (часть реального мира), на котором определяется набор данных и методов манипулирования с ними для решения конкретных задач или исследований.
Для того чтобы полностью отобразить объекты реального мира и все их свойства, понадобилась бы бесконечно большая база данных. Поэтому необходимо свести множество данных к конечному объему, легко поддающемуся анализу и управлению. Это достигается применением моделей, сохраняющих основные свойства объектов исследования и не содержащих второстепенных свойств. Поэтому первым этапом разработки информационной системы или технологии ее применения является обоснование выбора моделей данных для создания информационной основы системы, позволяющей в дальнейшем реализовать автоматизированный доступ к данным с целью их анализа и принятия решения.
Известные средства описания данных ориентируются на формы представления информации в виде синтаксических и семантических моделей. К числу синтаксических моделей относятся реляционная, сетевая и иерархическая модели данных, семантические модели – это модель сущностей и связей, модель семантических сетей.
Модель как знаковая система должна содержать три характеристики: синтаксис, семантику и прагматику. Этот подход определяет содержание атомарной (элементарной) модели, как элементарной единицы данных, включающей в себя правила построения объекта, свойства объекта, значения свойств. Разнообразие атомарных моделей создает условия для построения множества моделей данных.
Семантическая модель – полуформальный механизм, используемый для описания смыслового содержания базы данных, т.е. концептуальной семантики; схема семантической модели выполняет роль спецификации информации, что позволяет разработчику точно и исчерпывающе представить содержимое базы данных, не зависимо от конкретной СУБД.
Семантическое моделирование взаимосвязано с задачами кодирования и лингвистического обеспечения, поэтому оно в большей степени используется на уровне сбора первичной информации. Это также обусловлено большим объемом и разнообразием входной информации, сложностью ее структуры, возможным наличием ошибок.
Направление научных исследований, получившее название семантического моделирования сложилось в середине 70-х годов. Термин «семантическая модель» был раскрыт в работах Абриэля (1974), Сенко (1975), Чена (1976), Бахмана (1977) и других.
Общеизвестно, что семантические модели данных должны отвечать следующим требованиям:
- обеспечивать интегрированное представление о предметной области;
- понятийный аппарат модели должен быть понятен как специалисту предметной области, так и администратору БД;
- модель должна содержать информацию, достаточную для дальнейшего проектирования экономической информационной системы.
В семантических моделях используются конструкции естественного языка, называемые высказываниями, декомпозиция которых невозможна без утраты смысла.
Элементами высказываний служат атомарные факты. Атомарный факт – это любой объект, разложение которого на другие объекты в рамках данной предметной области не производится. Атомарный факт представляется тремя компонентами:
(x, y, t),
где x – множество объектов О1, О2, …, Оk;
y – свойство или связь объектов;
t – время.
Объекты могут вступать в отношения двух типов – обобщения, когда один объект определяется в виде множества других объектов, и агрегации, когда объект соотносится с именем действия, в котором он может участвовать. Обобщения и агрегации могут образовывать иерархические структуры. Эти абстракции применяются в управлении файлами: агрегации – при конструировании файла для группирования полей в запись; обобщения – для представления множества записей общим типом объекта – файлом, а также для выборки из файла множества записей. На рис 20 и 21 приведены примеры иерархии обобщения и агрегации.
Известно достаточно большое число семантических моделей, наиболее известными из которых являются модель сущностей и связей и модель семантических сетей.
Модель «сущность-связь» или ER-модель – это отражение реального мира в виде сущностей (Entity) и связей между ними (Relationship). На схеме сущности изображаются прямоугольниками, связи ромбами. Число связываемых объектов указывается цифрой на линии соединения.
Теоретической основой этого подхода является известная модель, введенная М. Ченом в 1976 году и получившая широкое распространение в качестве средств концептуального проектирования баз данных.
Различные методики построения ER-моделей анализируются по следующим основным аспектам:
Терминологический аппарат, лежащий в основе методики.
Семантические возможности модели для отображения различных ситуаций реального мира.
Наличие алгоритма перехода от ER-модели к различным даталогическим и конкретно к реляционной даталогической модели.
Эффективность алгоритма перехода.
Технология построения модели, сложность процесса моделирования.
 |

 |
||||||||||||||
 |
||||||||||||||
 |
||||||||||||||
 |
 |
|||||||||||||
 |
 |
 |
Как уже упоминалось, идеи Чена являются своеобразным стандартом для построения ER-моделей. Другие модели могут отличаться набором графических символов, некоторыми особенностями моделирования, но основные правила остаются теми же.
Под сущностью понимается нечто, что можно идентифицировать, при этом проектировщик должен суметь определить какие именно сущности имеют значение для моделирования, а какие – нет.
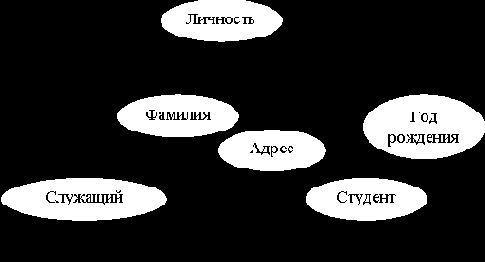 |
|||||||||
 |
 |
 |
 |
||||||
Характеристики основных методологий ER- моделирования Табл. 2
|
Наименование характеристик |
Чен |
Бахман |
Джексон |
Диго |
Oracle |
IDEF |
|
Количество видов сущностей |
1 |
1 |
1 |
3 |
2 |
3 |
|
Количество видов отношений по числу входящих экземпляров |
3 |
3 |
3 |
3 |
3 |
2 |
|
Наличие n-арных отношений |
+ |
- |
+ |
- |
- |
- |
|
Возможность отображения отношений «род-вид» |
- |
+ |
- |
+ |
+ |
+ |
|
Вид даталогической модели, для которой предложены алгоритмы преобразования |
сетевая |
сетевая |
реляционная |
сете-вая реля-ционная, на инв. файлах |
реляционная |
реля-ционная |
|
Наличие средств автоматизации |
- |
- |
- |
- |
+ |
+ |
N- арные связи;
рекурсивные связи;
несколько связей для одной и той же пары объектов.
Например,
 |
Таким образом, соответствующий тип инфологической модели при проектировании АЭИС способствует правильному выбору алгоритма перехода к даталогической модели и позволяет дать рекомендации по проектированию физической структуры базы данных.
Элементами семантического представления являются понятия и семантические (смысловые) отношения между ними. Теоретико-графовое представление такого уровня называется семантической сетью. Аппарат семантических сетей является естественной формализацией ассоциативных связей, которыми пользуется человек при извлечении каких-то новых фактов из имеющихся. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т. п.
Семантическая сеть – это ориентированный граф с помеченными дугами.
Обычно в семантической сети предусматривается четыре категории вершин:
понятия (объекты);
события;
свойства;
значения.
Понятия – это константы или параметры, которые определяют физические или абстрактные объекты. События – это действия, происходящие в реальном мире, и определяются указанием типа действий и ролей, которые играют объекты в этом действии. Свойства используются для представления состояния или модификации понятий и событий.
Сведения семантической сети образуют сценарий, который является набором понятий, событий, причинно-следственных связей.
В семантической сети вершины могут обозначать экземпляры объектов и классы объектов. Например, Иванов – экземпляр типа Студент. Экземпляр может принадлежать более, чем одному классу. Иванов – Студент и Спортсмен. Различие между вершинами сети приводит к существованию трех дуг:
- дуга, соединяющая два экземпляра, соответствует утверждению;
- дуга между классом и элементом класса показывает пример элемента класса;
- дуга, связывающая два класса, определяет бинарное отношение классов.
Связи понятий образуют в общем случае сетевую структуру.
При установлении структуры понятий используются две обязательные связи:
связь «есть-нек» (от слов есть некоторый), направленная от частного понятия к общему и показывающая принадлежность элемента к классу;
связь «есть-часть», показывающая, что объект содержит в своем составе разнородные объекты, не подобные данному объекту.
Для составления семантической сети предварительно выделяются простые отношения, которые характеризуют основные компоненты события. В первую очередь из события выделяется действие, описываемое глаголом. Далее необходимо определить объекты, которые действуют и над которыми осуществляются действия.
Обычно рассматриваются следующие падежи:
агент – предмет, являющийся инициатором действия;
объект – предмет, подвергающийся действию;
источник – размещение предмета перед действием;
приемник – размещение предмета после действия;
время – указание на то, где происходит событие;
место – указание на то, где происходит событие;
цель – указание на цель действия.
Семантические сети имеют ряд преимуществ:
описание событий и объектов производится на языке, близком к естественному;
возможность выделить из полной сети, представляющей всю семантику некоторый участок, который охватывает необходимые в данном запросе смысловые характеристики;
обеспечивается возможность сцепления различных фрагментов сети;
возможные отношения между понятиями и событиями образуют достаточно небольшое, хорошо формализованное множество.
На рисунке 23 представлен пример семантической сети .
Выбор конкретной модели при описании предметной области определяется рядом требований, таких как: теоретическая основа модели данных; наглядность, визуальная представимость; легкость информационного моделирования; простота декомпозиции; совместимость с другими моделями; независимость от аппаратной реализации.
Личность

есть-нек
изучает

 |
 |
есть-часть есть-часть
есть-часть
№ зачетной книжки Фамилия Факультет Год рождения
Рис. 23. Семантическая сеть объекта «Личность»
§ 4.2. Тезаурусы экономической информации
Сущность самоотображения системы наиболее точно выражается тезаурусом, который также считаем одним из видов информационного моделирования. Термин thesaurus был впервые применен еще в Х111 веке Брунетто Латини как название энциклопедии.
Термин «тезаурус» является общеупотребительным и общепринятым термином как элемент информационного языка, позволяющего фиксировать парадигматические* отношения и отношения синонимии между понятиями предметной области.
Тезаурус – это словарь-справочник, в котором перечисляются все лексические единицы ИМЯ с синонимичными им словами, а также выражены все важнейшие смысловые отношения между лексическими единицами.
В общем случае тезаурусом принято называть конечное непустое множество Т слов t, отвечающих условиям:
§ Имеется непустое множество T0 Ì T, называемое множеством дескрипторов;
- Имеется симметричное, транзитивное рефлексивное отношение R Ì T
при этом отношение R называется синонимическим отношением, а слова t1, t2, отвечающие этому отношению, называются синонимическими дескрипторами;
- имеется транзитивное и несимметричное отношение K Ì T0 ´ T0, называется обобщающим отношением.
В случае, если два дескриптора t1 и t2 удовлетворяют отношению t1 K t2, то полагается, что дескриптор t1 более общий, чем t2.
В тезаурусе дескрипторы распределены по семантическим категориям, внутри категорий по семантическим типам.
Состав словарной статьи дескриптора переменный и зависит прежде всего от семантической категории дескриптора и семантического типа.
При построении тезауруса, в общем случае, широко используется аппарат информационного исчисления искусственного интеллекта, основанный на двоичной логике Аристотеля, непрерывной логике Заде, когнитивной графике Эйлера, языке диаграмм Чена, формальной грамматике Холмского.
Основные этапы разработки тезауруса можно свести к следующим:
1. Выбор источников лексики и отбор терминов.
2. Составление терминологического словаря.
3. Группировка терминов в тематические классы.
4. Формирование классов условной эквивалентности.
5. Установление парадигматических отношений.
6. Определение структуры тезауруса.
Для отбора лексического материала используют экономические документы, отражающие качественные и количественные характеристики объектов, а также толковые словари, справочники, классификаторы.
В терминологическом словаре каждому отобранному термину дается определение, соответствующее его экономическому смыслу. Все термины классифицируются в зависимости от функционального назначения в тематические классы.
При составлении тезауруса необходимо устранить многозначность (омонимия, полисемия). Они могут быть устранены лексикографически при редактировании терминологического словаря.
Омонимия – совпадение в звучании и написании разных слов, которые не имеют ничего общего ни по происхождению, ни по функционированию. Например, клетка (элементарная живая система) и клетка (для содержания животных).
Полисемия – перенос названия одного предмета на другие предметы на основании сходства (по форме, внутренним свойствам и т.д.). Например, сумка (предмет гардероба) и сумка кенгуру.
Синонимия – явление естественного языка, заключающееся в том, что одному предмету или явлению соответствует несколько слов. Устранение синонимии происходит путем группирования терминов в классы условной эквивалентности (КУЭ).
В КУЭ объединяются термины, между объемами понятий которых существуют отношения:
равнозначности, когда объемы понятий полностью совпадают (директория, каталог, папка);
перекрещивания, когда лишь часть объема одного понятия входит в объем другого понятия и, в свою очередь, лишь часть объема второго понятия входит в объем первого понятия (книга – монография);
подчинения, когда объем одного понятия составляет часть объема другого понятия (дисковод – системный блок);
внеположенности, когда объемы понятий полностью исключают друг друга и при этом не исчерпывают области предметов, о которых ведутся рассуждения (чашка, ложка: общий класс – посуда).
Любое из этих отношений может быть использовано для группировки в классы условной эквивалентности.
В каждом синонимическом ряду выделяется слово, которое может заменить любое слово класса. Оно называется дескриптором и имеет форму существительного.
Основными критериями для выбора термина являются:
- полнота выражения смыслового значения данного класса условной эквивалентности;
- значимость термина для поиска информации;
- научно-техническая точность термина и возможность его использования для индексирования;
- распространенность термина;
- краткость термина и понятность его для неспециалиста;
- частота появления термина в различных источниках;
- частота первичного использования термина при индексировании и поиске.
Парадигматические отношения могут выражаться четырьмя способами:
- лексикографически;
- при помощи таблиц;
- аналитически;
- графически.
Лексикографический способ предполагает наличие специальных помет, которые указывают, в каких парадигматических отношениях находится данный дескриптор с заглавным.
Табличный способ заключается в том, что под заглавным дескриптором записываются со сдвигом на несколько знаков вправо дескрипторы, находящиеся с заглавным дескриптором в определенном отношении. Такой способ применяется в библиотечно-библиографических классификациях.
При аналитическом способе парадигматические отношения выражаются при помощи структуры кодов дескрипторов.
Примером применения аналитического способа может служить универсальная десятичная классификация.
Графический способ предполагает применение различных графических схем.
Для выражения парадигматических отношений наиболее часто используется сочетание лексикографического и табличного способов с применением обозначений, рекомендуемых ГОСТом:
н – нижестоящий видовой дескриптор по отношению к заглавному дескриптору;
в – вышестоящий родовой дескриптор по отношению к заглавному дескриптору
ц – дескриптор находится в отношении – целое к заглавному дескриптору;
ч - дескриптор находится в отношении – часть к заглавному дескриптору;
с – ключевое слово находится в отношении синонимии к заглавному дескриптору;
см – отсылка от ключевого слова к дескриптору.
Тезаурус представляет собой совокупность расположенных с алфавитном порядке дескрипторных статей. Например,
Для систематизации обширного класса сведений может использоваться новый тип информационных моделей – гипертекст или нелинейный текст, совмещающий положительные свойства энциклопедии, монографии и тезауруса.
Термин гипертекст введен В.Бушем и конкретизирован Т. Нельсоном Гипертекст – это многомерный текст, чтение которого можно осуществлять в нескольких направлениях.
Математическую модель гипертекста представляется следующим образом:
Пусть M и R конечные непустые множества
M = {m1, m2, …,mn}; R = {R1,R2, …, Rk}.
Элементами множеств М и R обозначены объекты и отношения между ними. Тогда гипертекст, в наиболее общем виде, описывается как совокупность следующих четырех компонентов:
Г0 = (Е, I, S, Q),
где Е – тезаурус гипертекста;
I – информационная составляющая гипертекста, включающая в себя содержание информационных статей Ii, в которые помещаются сведения о всех mi Î M , т.е. I =

S – алфавитный (или хронологический) словарь всех наименований mi Î M;
Q – список главных тем гипертекста.
Тезаурус гипертекста состоит из тезаурусных статей, каждая из которых может быть представлена в виде:
ti = { mi, Ami},
где ti- тезаурусная статья объекта mi;
Ami – множество объектов, с которыми mi связан отношениями из R указанием типа отношения.
Тезаурус является главной частью гипертекста, служащей основой для систематизации и поиска сведений. Попытка описания гипертекстовой структуры в рамках реляционной модели не дает желаемого результата в силу статичности самой модели и отсутствия поддержки ассоциативного поиска Попытки формализации гипертекстовой модели и создания некоторых стандартов были предприняты Бейбером , Дейкстрой , Фурутой, Скотсом и др. В основном авторы моделей используют сетевой подход к построению моделей. Гипертекстовая структура, представляемая в виде сети с вершинами (концептами) и связями (отношениями), является наиболее удобной для создания больших интеграционных систем. Вершина может содержать текст, графику, анимацию, аудио, видеофрагменты и другие формы информации. Связи между вершинами двунаправленные, посредством чего осуществляется навигация по сети в различных направлениях.
Примером, свидетельствующим о популярности гипертекстовых технологий, является организация всемирной информационной сети Internet.
Гипертекстовая модель обладает рядом недостатков, связанных с жесткостью существующих связей и условий поиска, невозможностью передачи информации из одной системы в другую.
Тем не менее, модель находит широкое применение в системах обработки экономической информации, т.к. гипертекстовая структура дает возможность связывать разнотипные информационные объекты в единое приложение, поддерживает ассоциативный поиск. Гипертекстовая модель может применяться для семантического моделирования, анализа и сравнения экономических категорий, установления корректности понятий и терминов, в учебных процессах, для системного контроля фонда нормативно-правовых документов по вопросам экономики на полноту, непротиворечивость, избыточность.
В заключении отметим, что анализ основных типов моделей экономических систем позволяет сформулировать требования, которым должен отвечать аппарат моделирования:
§ обеспечивать учет особенностей экономической информации;
§ обеспечивать разнообразие (видов) форм представлений объектов предметной области (графическое, текстуальное, алгоритмическое и др.);
§ позволять строить многомерное отображение предметной области, на основе которого могут быть формализованы требования к системе обработки данных
§ обеспечивать устойчивость проектных решений к изменениям информационной сферы предметной области;
§ давать возможность описывать широкий класс понятий, используемых для адекватного представления объектов предметной области;
Выбор конкретной модели при описании предметной области определяется рядом требований, таких как: теоретическая основа модели данных; наглядность, визуальная представимость; легкость информационного моделирования; простота декомпозиции; совместимость с другими моделями; независимость от аппаратной реализации.
Вопросы и задания
1. Какие условные обозначения рекомендованы ГОСТом для определения парадигматических отношений и отношений синонимии?
2. Что такое тезаурус и какова его роль в экономических информационных системах?
3. Назовите падежи, используемые в семантических сетях для представления событий и действий?
4. Какие Вы знаете синтаксические модели данных и семантические модели и в чем их различие?
5. Что такое атомарный объект и атомарный факт?
6. Назовите варианты соответствий между сущностями и связями?
7. Каковы недостатки модели "сущность-связь"?
8. Назовите принципы, по которым термины объединяются в классы условной эквивалентности?
Глоссарий
Агрегация – процедура структуризации данных. Заключается в конструировании объекта из других базовых объектов, на основе чего создается агрегативная модель. Соотносится с понятием «есть некоторые».
Атрибут – элементарное данное, описывающее свойство сущностей.
Ациклическая база данных – класс реляционных баз данных, для которых характерна однозначная декомпозиция на основе многозначных зависимостей.
Граф – графическая схема, включающая основные элементы графа, называемые вершинами и дугами.
Граф ориентированный – граф, в котором каждое ребро ориентировано, т.е. определен путь от одной вершины к другой.
Даталогическая модель – модель логического уровня описания системы, состоящая из логических записей и отображения связей между ними безотносительно к виду реализации.
Домен – множество значений атрибута.
Иерархическая модель – модель структуры процесса или системы, структурная схема которой является ориентированным графом. Состоит из совокупности исходных и порожденных типов записей, связанных одной или несколькими дугами. Допускает связи уровней типа один ко многим или один к одному.
Инфологическая модель – описательная модель предметной области, независимая от структуры данных. Обычно состоит из совокупности информационных объектов, атрибутов и отношений между ними. Отражает динамику предметной области.
Информационная система – взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, поиска обработки и выдачи информации по запросам пользователей.
Метаданные – дополнительные данные о данных.
Моделирование информационное – моделирование, связанное с созданием и преобразованием разных форм информации, например, например, графической или текстовой , в вид, задаваемый пользователем.
Моделирование семантическое – моделирование, связанное с задачами кодирования и лингвистического обеспечения.
Модель инвертированных файлов – частный случай сетевой двухуровневой модели данных, служит основой для современных информационно-поисковых систем.
Модель «сущность-связь» - графовая модель, дающая представление о предметной области в виде объектов, называемых сущностями, между которыми фиксируются связи. Для каждой связи определено число связываемых ею объектов.
Нормализация отношений – процесс преобразования отношений базы данных к той или иной нормальной форме.
Обобщение – процедура абстракции (структуризации) данных, соотносится с понятием « есть часть». Обобщение акцентирует сходство объектов, абстрагируясь от различий.
Отношение – множество кортежей, описывающих класс объектов.
Организация значений данных – относительно устойчивый порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между записями.
Первичный ключ – атрибут или комбинация атрибутов, значения которых однозначно идентифицируют каждый кортеж в реляционной модели.
Последовательная организация данных – записи располагаются в памяти строго одна за другой, без промежутков, в той последовательности, в которой они обрабатываются.
Предметная область – подмножество (часть реального мира), на котором определяется набор данных и методов манипулирования с ними для решения конкретных задач или исследований.
Реляционная модель – табличная модель данных, основным средством структуризации в которой является отношение.
Сущность – элемент модели (совокупность атрибутов и знаков), описывающий законченный объект или понятие.
Экономическая информация – информация об экономических процессах, таких как производство, потребление, распределение и т. д.
Экономическая информационная система – система, предназначенная для хранения, обработки, поиска и выдачи информации.
Экономический показатель – полное описание количественного параметра, характеризующего некоторый объект или процесс.
Список литературы
1. Бусленко Н.П. Моделирование сложных систем / Н.П. Бусленко. – 3-е изд. – М.: Наука, 1978. – 399 с.
2. Информатика: Учебник /Под ред. Н.В. Макаровой. – 3-е изд. – М.:Финансы и статистика, 1999. – 768 с.
3. Компьютерные системы и сети: Учеб. пособие/ В.П. Косарев и др.;Под ред В.П. Косарева и Л.В.Еремина. – М.: Финансы и статистика, 1999. – 464с.
4. Королев М.А. Теория экономических информационных систем / М.А. Королев, А.И. Мишенин , Э.Н. Хотяшов. - М.: Финансы и статистика, 1984. – 223 с.
5. Мишенин А.И. Теория экономических информационных систем / А.И. Мишенин. – М.: Финансы и статистика, 1999 г.
6. Цикритзис Д., Модели данных / Д. Цикритзис, Ф. Лоховски . - М.: Финансы и статистика, 1985. – 344 с.
7. Экономическая информатика /Под ред. П.В. Конюховского и Д.Н. Колесова. – СПб.: Питер, 2000. – 560 с.